Alles in Deckung, längerer Rant.
Ein Buch, welches mir immer wieder empfohlen wurde, ist „Blackout“ von Marc Elsberg *. Ein Blackout bezeichnet dabei üblicherweise einen unerwarteten, großflächigen Stromausfall. Langes Thema, über das man viel erzählen könnte *Videoidee notier*, aber dafür sind wir heute nicht hier. Der Streaminganbieter „Joyn“ hat auf Basis des Buchs nun eine Serie geschaffen. Die erste Folge ist nach Anmeldung gratis ansehbar, also werfen wir mal einen Blick rein. Prinzipiell haben Filme und Serien aus technischen Themenfeldern für mich immer einen gewissen Popcornfactor, da durch filmische Vereinfachung selbst bei guter Beratung teils wirre Erklärungen oder Aktionen auftreten.
Vorweg: Ich bin in vielen Bereichen nicht direkt aktiv, mein „Wissen“ stützt sich daher eher auf die öffentlichen Publikationen der Betreiber bzw. Techniker sowie geltende Normen. Nicht auszuschließen, dass ich ab und an mit meiner Einschätzung daneben liege. Hinweise gerne über die Kommentare oder direkt an mich.
Vorab ein Mini-Rant zu Joyn: Aktuell 7€/Monat für einen eher unbekannten Streamingdienst mit zweifelhafter Auswahl und keinen Inhalten >1080p erscheint mir doch eher gewagt. Ebenso scheint der Player keinerlei Funktionen zu bieten – Originalton? Untertitel? Manuelle Qualitätswahl? Widergabegeschwindigkeit? All dies suchte ich vergebens. Hinzu kommt eine sehr strikte DRM-Policy, welche für fremde Inhalte viele Browser und Betriebssysteme, unter Anderem auch alle PCs, Mediacenter und TVs auf Basis von Linux, vollständig ausschließt. Man tritt also all Jenen, die die Inhalte legal konsumieren wollen, vor’s Schienbein, während Menschen mit „bösen“ Absichten diesen „Schutz“ mit wenigen Tricks umgehen und die Inhalte ohne solche Gängelei genießen können.
Glücklicherweise ist die Blackout-Folge mit geringerem DRM versehen, also los geht es. Erster Eindruck: Ist der Monitor falsch eingestellt? Alles extrem dunkel und kaum zu erkennen. Ich verbuche es mal als Stilmittel und konzentriere mich fortan auf die technischen Aspekte.
Erste Technische Szene: Das Wasserkraftwerk Eibenstock in Sachsen. Gibt es tatsächlich – 1.7MW. Nicht unbedingt ein sonderlich nennenswerter Beitrag zum Netz, aber hey, I’ll take it. Im Dialog zwischen einer Person in der lokalen Leitstelle und einem Weiteren, der durch Gänge irrt, geht es darum, dass durch ein Länderspiel der Stromverbrauch höher als üblich wäre. Tatsächlich kann man Länderspiele teils in der Infrastuktur sehen, aber eher andersrum: In Pausen steigt der Strom- und – vor Allem – der Wasserverbrauch. Der Fernseher selbst geht im Rauschen der Stromverbraucher unter – eine einzige Mikrowelle benötigt mehr Strom als 10 Fernseher. All das ist nichts gegen Industrieanlagen, von denen viele beim abendlichen Länderspiel still stehen dürften. Also mehr als genug Reserven da.
„Warte mal, da stimmt was nicht“ ist die Aussage des Gangerkunders, welcher wohl den Chef mimen soll. Im Hintergrund hört man, das sich eine Drehzahl erhöht. Akustisch kein Kraftwerk, aber dann wäre vom Dialog auch nicht mehr viel übrig. Würde die Drehzahl eines (klassischen) Kraftwerks steigen, dann würde tatsächlich mit hoher Wahrscheinlichkeit etwas nicht stimmen. Plötzlich steigende Drehzahl wäre ein massives Problem – im Gegensatz zur vorherigen Diskussion aber ausgelöst durch sinkende Last, nicht steigende. Tatsächlich wird dieser Umstand und seine Folge aber später in der Folge auch korrekt erklärt. Man entscheidet sich für eine Notabschaltung um die Anlage zu schützen. Solche Abschaltungen bei kritischen Zuständen sollten eigentlich automatisch erfolgen. Es ist Sinn und Zweck eines Steuersystems Personal, Anlagen und Umwelt vor gefährlichen Betriebszuständen zu schützen. „Es ist ein Frequenzabfall“ heißt es zugleich vom Herren im Leitstand. Seltsam, denn ein Abfall der Frequenz ginge mit zu hoher Last und daher sinkender Drehzahl einher. Die Visualisierung – hm. Teils eher unsinnige Werte, aber immerhin sind die angezeigten Elemente durchaus für ein solches Wasserkraftwerk relevant – wenn auch grafisch etwas übertrieben.
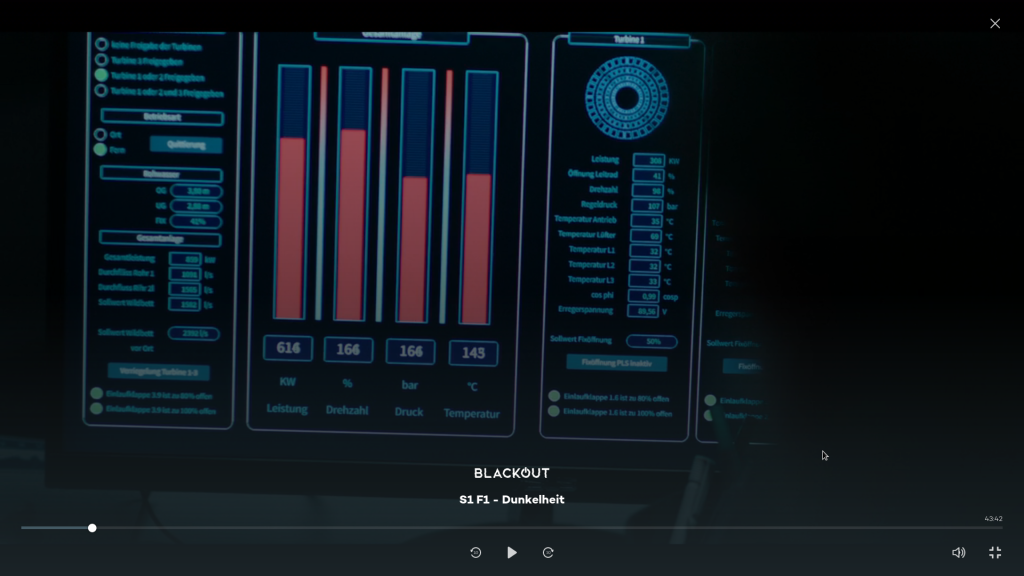
Bildausschnitt „Blackout“; © Wiedemann & Berg Television / Joyn
Aber zurück zur „Notabschaltung“. Der Herr in der Leitwarte läuft nun los – mehrere Treppen und Gänge entlang – um auf mehrere Knöpfe für die Notabschaltung zu drücken. Wat. Eine Notabschaltung ist für Notfälle, entsprechend ist sie auch schnell erreichbar und verbirgt sich nicht in abgelegenen Schaltschränken. Üblicherweise findet man eine (bzw. mehrere für mehrere Maschinen) auf dem Kontrollpult oder an der Tür des Kontrollraums. Im Steuerschrank einer Heizung bzw. kleinen Wasseraufbereitungsanlage – eine Kraftwerkssteuerung dürfte das gezeigte jedenfalls nicht sein – versteckt sich diese eher nicht. Auch ist das üblicherweise ein Knopfdruck und nicht ein Klavierkonzert. Anyway – das Kraftwerk fährt nun runter. Und das Licht geht aus. Hm, bei einer Kraftwerksabschaltung wird Licht & Co üblicherweise noch vom Netz weiterversorgt. Gingen wir davon aus, dass das Netz ausgefallen wäre (was eine Erhöhung der Drehzahl auslösen könnte) hätte wiederum das Steuersystem schon vorher die Anlage automatisch in einen sicheren Zustand versetzt.
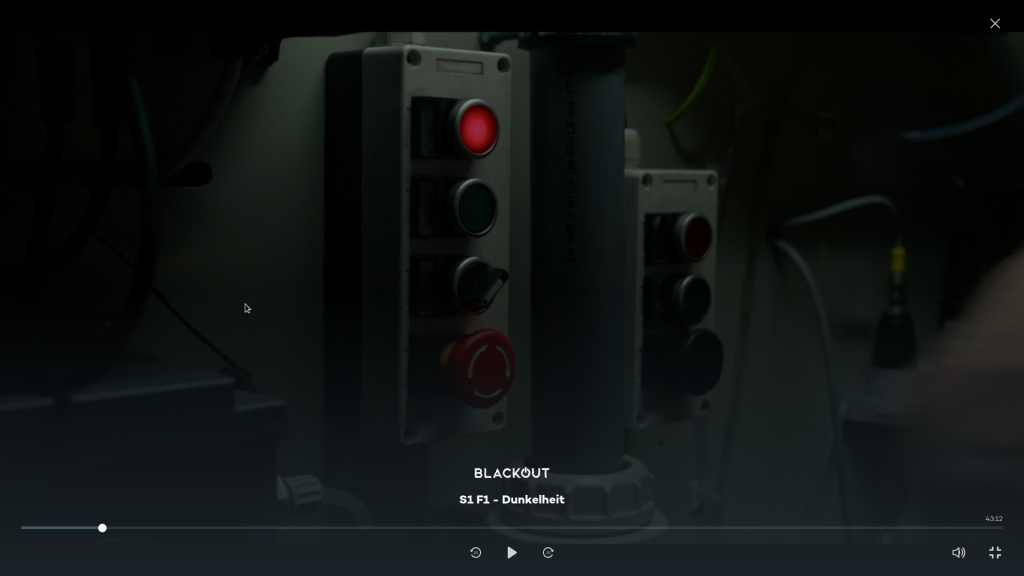
Bildausschnitt „Blackout“; © Wiedemann & Berg Television / Joyn
Nun folgen mehrere Szenen, die die Auswirkungen zeigen. Ausgefallene Ampeln? Joa. Dunkle Städte? Naja, Autos und Mobilgeräte würden weiterlaufen. Kein Handynetz? Schwierig – auch wenn es immer weniger wird gibt es durchaus noch Stationen mit Notstrom. Zumindest für eine kurze Zeit. Sicher, das Netz könnte durch die entstehende Flut von Anrufen überlastet werden, aber Personal von Ministerien (die gezeigte Dame arbeitet in der Story für das Innenministerium) hatten zumindest früher eine erhöhte Priorität auf ihren SIM-Karten. Also sagen wir es wäre halt ihr Privathandy. Zudem hat der Berliner Hauptbahnhof – oder sollte ich sagen die eher schlecht zurechtgephotoshopte Leipziger Messehalle – offenbar eine interessante Notausstattung: Der überdimensionale Bahnsteig – Grundfläche kostet dort offenbar nichts – wird zwar nicht beleuchtet, für die Aktualisierung der Fallblattanzeige ist aber Notstrom vorhanden.
Auch im Freizeitpark nebenan interpretiert man die Notsysteme eher lose: Ein Achterbahnzug haut durch den Beginn des Stromausfalls die Bremsen zu und kommt kopfüber zum stehen. Entwarnung für Alle, die sowas glauben: Nein. Die gezeigte Achterbahn hat einen Kettenlifthill am Anfang, also vermutlich im Zug selbst keinen eigenen Antrieb und üblicherweise auch keine aktiv gesteuerten Bremsen. Der Zug würde daher auch ohne Strom seine Fahrt fortsetzen und an der nächsten Blockstelle (bei kleinen die Station, bei größeren Anlagen zwischendrin) stehen bleiben. Diese Blockstellen sind dabei auch fast immer mit Stegen, Leitern und Ausstiegsmöglichkeiten für genau solche Fälle versehen. Die Steuerung sorgt dafür, dass zwischen der letzten und der kommenden Blockstelle immer nur ein Zug unterwegs ist. (Wer es genauer will: Es dürfte die Stahlachterbahn Huracan im Park BELANTIS sein, diese ist vom Modell Euro-Fighter des Herstellers Gerslauer Amusement Rides – die Blockstelle in der Mitte der Strecke, an der in Notfällen der Wagen anhalten würde, ist sehr deutlich zu erkennen.)
Weiter geht es im ICE. Von der Verschwenkung im Gang würde ich auf BR412 („ICE4“) tippen. Dort springt soeben lautstark der Notstrom an und sorgt für Licht im Waggon. Nochmal wat. Ich kann leider keine vollständigen Daten für den 412er finden, von vorherigen Modellen und den Rettungskarten ausgehend gehe ich aber sehr stark davon aus, dass über den Zug verteilt Blei-Gel-Batteriepacks für Beleuchtung und Steuergeräte genutzt werden. Diese sind dauerhaft aktiv und müssen nicht extra geschaltet werden, das Licht wäre also gar nicht ausgegangen. Einen Generator dürfte man im Zug nicht finden. Teils kann man mit den Batterien Rückspeisen und so die Klimaanlage betreiben, was die Geräusche erklären könnte, dennoch: Nope.
Weiter. Der Nachbar klingelt. Er könne kein Fußball schauen. Du bist doch Techniker, reparier das. Ich denke jeder Techniker kennt das – der Part ist mehr als realistisch.
Der kurze Lichtblick wird schnell getrübt: Der Techniker steht mit Laptop vor dem (trotz Stromausfall leuchtenden) Stromzähler und schaltet drahtlos den Strom wieder ein. Erstens: Es wurde/wird schon klargestellt, das alle Kraftwerke aus sind. Dann ist üblicherweise auch kein Strom am Zähler. Erst recht kann man ihn dann nicht drahtlos mit einem beliebigen Laptop wieder einschalten. Selbst wenn wir jetzt mutmaßen, dass der Techniker den Zähler bereits vorher präpariert und mit WLAN ausgerüstet hat, den zugehörigen Router per Akku mit Notstrom betreibt und den internen Datenbus angezapft hätte: Ohne Stromnetz ist der Controller des Smartmeters üblicherweise aus. Andere Punkte passen aber: Einige Smartmeter-Modelle haben Möglichkeiten den Strom durch Fernsteuerung zu unterbrechen („remote disablement“). Auch die Gefahr, dass Kriminelle in diese Systeme eindringen können, ist nicht unwahrscheinlich. Ebenso würde ich hoffen, dass die aktuellen Smartmeter keinen 3.19er Linux-Kernel nutzen – der ist schon was länger EOL. Die gezeigten Tools zur Kontrolle sehen ebenfalls nicht sonderlich unrealistisch aus.
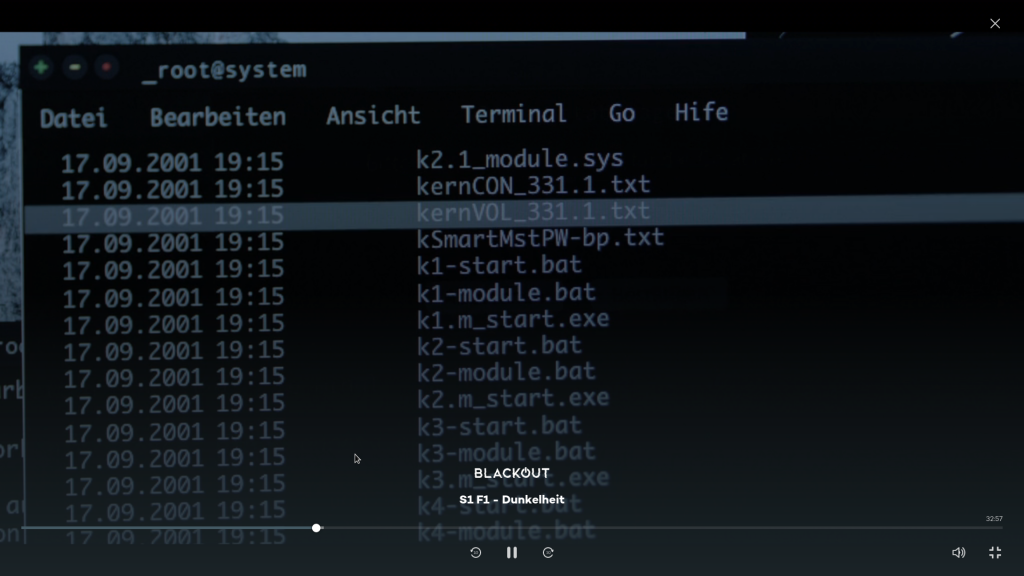
Steuerprogramme für Smart-Meter. EXE/BAT/SYS deutet auf Windows hin. Art und Anzahl der Dateien sind realistisch. Bildausschnitt „Blackout“; © Wiedemann & Berg Television / Joyn 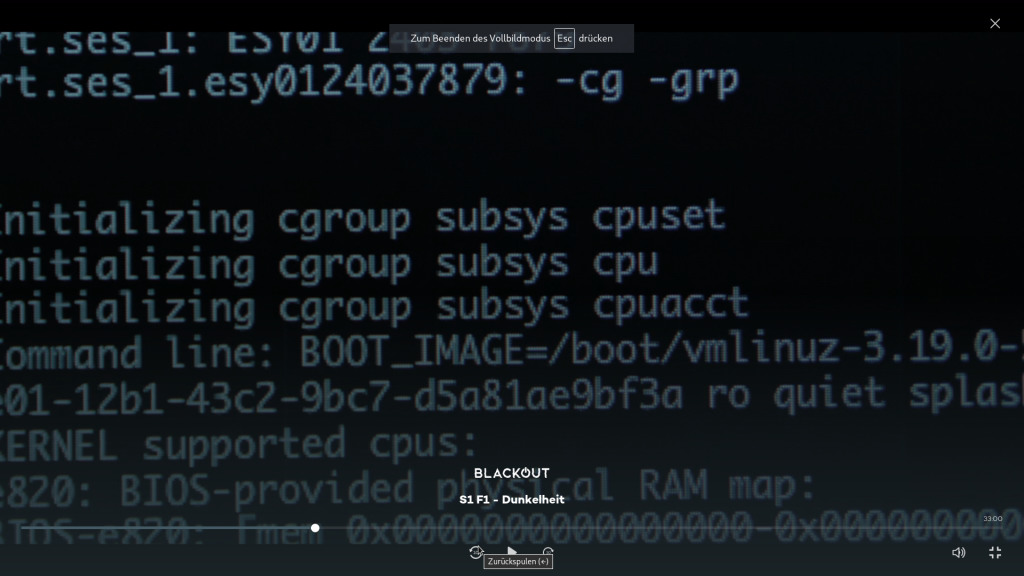
Meldungen eines Smart-Meters. Offenbar Boot-Log eines älteren Linux-Systems. Bildausschnitt „Blackout“; © Wiedemann & Berg Television / Joyn
Weiter geht es zum Berliner Innenministerium. Auch hier ist der Strom aus. Ich würde darauf wetten, dass es auch hier eine Unterbrechungsfreie Stromversorgung gibt, bei Ausfällen übernehmen also Batterien bis ggf. Generatoren laufen. Üblicherweise alles automatisch, bei günstigeren Anlagen eventuell mit einigen Sekunden umschaltzeit. Da die Protagonistin in der Zwischenzeit vom Bahnhof zum Ministerium gelaufen ist sollte die Versorgung längst in Betrieb sein. Ebenso reicht der Notstrom weder für die Schranke noch für eine brauchbare Innenbeleuchtung – wohl aber um die Schiebetüren am Eingang zu öffnen. Im Hintergrund bauen Techniker mit Verlängerungskabeln und Baustrahlern den Notstrom auf. That’s not how this (usually) works.
Es folgt eine Erklärung, dass es durch den gleichzeitigen Ausfall mehrere Hauptstromleitungen zu ungewöhnlichen Spannungsschwankungen gekommen wäre, welche sonst nur Millisekunden andauern würden. Puh. Interessante Technik, denn das Umschalten von Höchstspannungstrassen dürfte eher nicht in Millisekunden erfolgen. Der beschriebene Dominoeffekt ist aber durchaus korrekt – eine lokale Störung kann im ungünstigsten Fall das gesamte europäische Netz kippen.
Notstrom hätten Krankenhäuser und Ministerien – aber nur für bis zu 48 Stunden. Ja und nein – richtig ist, dass die Tanks natürlich nicht ewig halten, für diese Fälle gibt es jedoch Lieferverträge mit Firmen, die (zumindest auf dem Papier) ebenso über Notstrom zum betanken der Lieferfahrzeuge verfügen. Ganz so schnell ist das Licht in so versorgten Einrichtungen also nicht aus. Ebenso verfügen Hilfsorganisationen und Energieversorger über Aggregate und Netzersatzanlagen um an kritischen Stellen aushelfen zu können.
„Die Energieversorger sind optimistisch. In ein bis zwei Stunden haben sie das Problem gelöst“. So vermeldet der Herr im Anzug. Eine Szene, die ebenso realistisch erscheint. Personen in Führungsebenen neigen leider – insbesondere in Kriesen – häufig dazu Probleme kleinzureden und kaum haltbare Zusagen zu machen. Bei eine Systemtrennung im Januar 2021, bei welcher noch Strom da war, brauchte man über eine Stunde um einen „normalen“ Zustand zu erreichen. In zwei Stunden einen Schwarzstart hinzulegen klingt da doch sehr ambitioniert.
Im Kraftwerk setzt man derweil das SCADA-System zurück. Jepp, Supervisory Control and Data Acquisition, so heißen die Steuersysteme wirklich – Pluspunkt für richtiges Fachwort. Es zeigt sich aber wieder eine eher ungewöhnliche Priorisierung: Weiterhin kein Licht im Kontrollraum, aber genug Strom für Tröten und Dekorationsbeleuchtung. Was das Raumschiff(?) auf dem Zweiten Monitor angeht – hm, fällt mir schwer ein so langgezogenes Diagramm in einem Wasserkraftwerk zu verorten.
Zurück zum „Hacker“: Der ist nun auf dem Weg zur Zentrale des Energieversorgers. Auf dem Weg stellen sie fest, dass Tanken nicht möglich ist. Korrekt, nur wenige Tankstellen sind mit einer Notstromversorgung ausgestattet. Selbst wenn wären diese oft kritischen Verbrauchern, also z.B. Rettungskräften, vorbehalten. Er hängt sich an eine Gruppe Techniker und betritt das Gebäude. Ebenfalls nicht ungewöhnlich: Social Engineering – wer passend auftritt wird oft nicht hinterfragt. Eine Leiter ersetzt viele Schlüssel. Er erzählt von seinen Entdeckungen, wird in einen Raum begleitet und letztendlich durch eine Anti-Terror-Einheit gewaltsam festgenommen. Leider nach wie vor ebenfalls nah an der Wahrheit. Viele Firmen und Einrichtungen nehmen Hinweise auf Sicherheitslücken nicht wirklich wohlwollend auf. Zuletzt hatte die CDU eine Sicherheitsforscherin angezeigt, welche der Partei gravierende Sicherheitslücken in einer Wahlkampf-App gemeldet hatte. Teils scheint es, dass es in Deutschland für Forscher weniger gefährlich ist Sicherheitslücken auf dem Schwarzmarkt zu verkaufen und so Dritte in Gefahr zu bringen anstatt die zuständigen Stellen auf solche Lücken hinzuweisen und so Firmen und deren Kunden vor weiteren Schäden zu bewahren.
Alles in allem hinterließ die Folge bei mir einen gemischten Eindruck. Viele der Konzepte sind nah an der Wahrheit, bei anderen kann sich mein Kopf nur der Tischplatte annähern. Zum Verhängnis wird der Folge dabei, dass man die Technik sehr in’s Rampenlicht rückt – Fehler die bei B-Filmen wie 380.000V * in der Nebenhandlung untergehen werden hier passend eingerahmt und über Minuten plattgetreten. Am Ende ist die Sache für mich angesichts der mangelnden Verfügbarkeit und der technischen Fehlern recht klar: Es dürfte bei der einen Folge bleiben. Eventuell werfe ich später nochmal einen Blick drauf, wenn sie auch über andere Quellen verfügbar ist. Dann aber mit passender Flasche für das „ist Unfug“-Trinkspiel.