No space left on device
Wer diese Nachricht sieht hat meist etwas Arbeit vor sich. Aber was, wenn der Speicher eigentlich gar nicht so voll sein sollte? Nun, dann muss man auf die Jagd gehen.
Vorab: Ich werde mich hier auf Befehle für die Kommandozeile beschränken, da sich diese sowohl auf Desktop-Rechnern mit GUI als auch Servern nutzen lassen. Auch gehe ich von einem „einfachen“ Dateisystem ohne Kompression, Snapshots oder Subvolumes aus.
Fall 1: Es ist voll – Belegung analysieren.
Die einfachste Variante: Irgendwas belegt tatsächlich den Platz. Dies ist der Fall, wenn die Ausgabe von du -shx / bzw. du -shx /dein/ordner tatsächlich etwa dem „Used“-Wert aus df -h / bzw. df -h /dein/ordner entspricht.
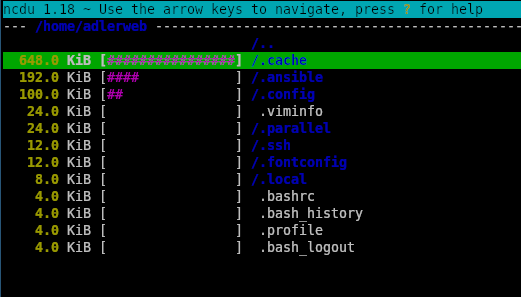
Für diesen Fall gibt es viele Tools, welche bei der Analyse helfen können, z.B. ncdu, welches sich in fast allen Paket-Managern finden sollte. Mit ncdu -x / bzw. ncdu -x /dein/ordner ermittelt es die Dateigrößen und stellt diese in einer TUI dar. Über die Pfeiltasten kann man zwischen den Dateien und Ordnern wechseln, mit Enter kommt man in den Order bzw. bei .. wieder zurück und mit d kann man die Datei direkt löschen.
Fall 2: Es ist noch voll – Gelöschte Dateien
Wenn der Usage-Wert aus df größer als jener aus du ist, dann können gelöschte Dateien im Spiel sein. Zumindest, wenn diese noch geöffnet ist. Nehmen wir ein Beispiel: Wir haben eine 4GB ISO-Datei im Ordner, diese binden wir in eine VM ein. Etwas später stellen wir Fest, dass wir die Datei ja eigentlich nicht mehr brauchen und löschen sie aus dem Ordner. Nun sollte man erwarten, dass im Ordner wieder 4GB frei sind, oder? Sind sie nicht, denn wir haben die ISO ja noch in der VM eingebunden, daher hat Linux nur vorgemerkt, dass die Datei gelöscht werden soll, gibt den Speicher aber erst wieder frei, wenn diese nirgendwo mehr in Verwendung ist. Ähnliches kann auch beim Überschreiben auftreten, da Linux die vorherige Version verfügbar hält, so lange diese von einem Prozess genutzt wird.
Die einfachste Möglichkeit solche Situationen zu beheben ist der Holzhammer: Ein Reboot beendet alle Prozesse, entsprechend ist auch nichts mehr geöffnet und alles Markierte verschwindet tatsächlich. Wer etwas feinfühliger sein möchte kann schauen, welcher Prozess derzeit bereits gelöschte Dateien verwendet. Die volle Liste gibt es mit . Etwas übersichtlicher macht es der Befehl *lufthol* lsof | grep deleted | awk '{if ($7 > sizes[$9]) {sizes[$9] = $7; cmd = "ps -o comm= -p " $2; cmd | getline name; close(cmd); names[$9] = name; pids[$9] = $2}} END {for (file in sizes) print sizes[file], names[file], pids[file], file}' | sort -nr | numfmt --to=iec
Dieser Zeigt jede gelöschte, aber noch geöffnete Datei 1×, die Größten finden sich ganz oben in der Ausgabe. Hier sind ggf. auch andere Speicherbereiche wie memfs oder /dev/shm/… mit aufgelistet, welche für die Dateisysteme nicht relevant sind.
Hier hat z.B. ein qemu-Prozess mit der PID 32387 einen für uns nicht relevanten memfd mit 32 Gigabyte. Ein systemd-Teil mit der PID 2448 hält wiederum 13MB durch die Datei /usr/lib/udev/hwdb.bin in Beschlag, welche zwischenzeitlich überschrieben wurden. Mit diesen Informationen kann man die zugehörige Software dann gezielt beenden bzw. neu starten um den Speicher wieder freizugeben.

Fall 3: Es ist doch voll – Mount in vollem Ordner
Ein etwas anderer Fall, bei dem sich df und du unterscheiden, kann auftreten, wenn man mit mehreren Partitionen oder Datenträgern arbeitet. Auch hier wieder ein Beispiel: Wir haben eine Festplatte mit installiertem Linux. Unter /mnt/iso/ speichern wir jetzt 5 verschiedene Linux-ISOs mit je ca. 2GB, belegen also 10GB. Nun merken wir, dass wir mehr Platz benötigen, bereiten eine zusätzliche Festplatte vor und hängen diese unter /mnt/iso/ ein. Nun sind die ursprünglichen Dateien ja noch unter /mnt/iso/ gespeichert, da dort aber ein anderes Dateisystem eingehangen ist, wird der Pfad bei du (oder auch ncdu) ignoriert. Ähnliches habe ich auch häufiger bei der Verwendung mäßig stabiler Software wie Docker entdeckt – dies „vergisst“ bei einigen Container-Neustarts einige mounts mitzunehmen und schreibt die Daten dann nicht auf die Datenpartition, sondern, für das Hostsystem erst mal unsichtbar, auf den Datenspeicher des Root-Dateisystems. Um dies zu analysieren verwende ich gerne einen bind-mount, diese nehmen keine anderen Dateisysteme mit und schaffen so eine Stelle, um mit ncdu das komplette Dateisystem zu erfassen.
mkdir /tmp/bind
mount -o bind / /tmp/bind
ncdu -x /tmp/bind
# Nachdem man fertig ist
umount /tmp/bind
rmdir /tmp/bindFall 4: Es ist voll kaputt – Dateisystemfehler
Natürlich kann es auch immer mal vorkommen, dass das Dateisystem tatsächlich einen Fehler hat und daher den freien Speicher falsch berechnet. Hier hilft dann oft (vorzugsweise von einem Live-System) die jeweiligen Scan- und Reparaturtools zu starten. Meist sollte ein fsck /dev/yourdevice das passende Programm auswählen.