Im Speicherumfeld gibt es einige All-in-one-Dateisysteme, welche viele Funktionen wie RAID, Volume Management, Snapshots, verteilen auf unterschiedlich schnelle Geräte, Kompression u.v.A. ineinander Vereinen. Am bekanntesten sind ZFS, welches jedoch lizenztechnisch schwierig ist, und BTRFS, welches – zumindest bei mir – nicht grade für seine Datensicherheit bekannt ist. Bcachefs verspricht diese Probleme zu lösen und noch mehr Funktion zu unterstützen. Ende 2023/Anfang 2024 soll das System das erste mal im stabilen Kernel verfügbar sein, also schauen wir mal wie man das nutzt.
(Achtung, Rant-Character. Wer das nicht mag findet die Lösung in den letzten 3 Absätzen)
Heute also mal wieder Docker. Ein stetiger Quell an Problemen. Ursprünglich war meine Anforderung gar nicht so kompliziert: Per docker-compose soll eine Multi-Container-Applikation aus- und wieder eingeschaltet werden. Also: docker-compose down und warten. Leider scheiterte der Prozess bereits an dieser Stelle aufgrund eines Timeouts. Das Schreiben großer Caches beim Beenden benötigt eben seine Zeit. Sicher, es gäbe -t oder stop_grace_period, aber wie das oft so ist: Wer auch immer vorher damit gearbeitet hat, hat es natürlich nicht dokumentiert oder konfiguriert.
Nunja, der docker-daemon sollte die zugehörigen Container trotz des Timeouts im Frontend noch abarbeiten – entsprechend war nach kurzer Bedenkzeit in docker ps -a auch kein Container mehr zu sehen, der zur Applikation gehört.
Alles gut? Leider nein. Das folgende docker-compose up weigerte sich beharrlich die Container wieder zu starten. Es versuchte immer noch, die Überreste der alten Struktur, insbesondere die Netzwerke, zu löschen, und scheiterte:
ERROR: error while removing network: network application_network id XXX has active endpoints
Active? Interessant, denn in docker ps -a war ja definitiv nichts mehr aktiv. Auch ein manuelles docker network remove application_network behauptete weiterhin, dass es die ID noch gäbe.
Error response from daemon: error while removing network: network application_network id XXX has active endpoints.
Ein docker network inspect application_network verriet: Die nicht mehr gelisteten Container sind wohl doch noch da – zumindest so halb. Also gehen wir auf Zombie-Jagd.
Die Lösung: Erst trägt man mit docker network inspect application_network | grep Name die Namen der verbliebenen Containerreste zusammen. Im Anschluss kann man über docker network disconnect ein Entfernen erzwingen.
for i in application_db_1 application_es_1 application_redis_1 application_nginx_1 ;do docker network disconnect -f application_network $i ;done
Abschließend entfernt man mit docker network remove application_network das Netzwerk. Danach sollte einem erneuten Start nichts mehr im Wege stehen.
Das hatte ich auch noch nicht. Laptop mit #NVME. Factory Windows 10 funktioniert, kein Secureboot o.Ä. Aber unter #Linux? NVME in lsblk nicht zu sehen. In lspci schon. Dmesg faselt was von Initialisierungsfehlern.
Die Lösung: Ein Firmware-Bug des Herstellers #WD#WesternDigital. Spricht man sie mit aktuellem NVME-Commandset an, beginnt die #SSD zu kotzen. Lösung: älterer Kernel oder Firmware aktualisieren (there is a bootable version…). Andere Hersteller hatten wohl auch schon mal sowas.
Ein Passwort alleine ist heute an vielen Stellen nicht mehr ganz Zeitgemäß. Oft wird heute ein zweiter Faktor genutzt. Diesmal daher ein kleiner Überblick über gängige Faktoren und ein Blick darauf, wie mein FIDO2- bzw. U2F-Sticks für Linux-Systeme und OpenSSH nutzen kann.
Inhalt
00:00 Vom Passwort zu 2FA
01:40 Faktoren: Wissen, Haben, Sein
02:00 Sein – Biometrische Faktoren
03:21 Haben – Smartcards & Co
03:54 Push-Techniken: SMS/Mail
04:28 Push-Techniken: Apps
05:05 TOTP
07:45 FIDO/U2F
11:30 OS-Login mit U2F / PAM unter Linux
20:07 SSH-Login mit U2F
23:31 Fazit
Ergänzungen
00:55 – Foto „Cyber“ von erdbeernaut · CC0
09:36 – Wobei das in den meisten Fällen nicht zu empfehlen ist
Selbst gekauft/allgemeine Werbegeschenke einer Konferenz, wo kostenpflichtig selbst bezahlt, zum Zeitpunkt des Videos nichts mit den Herstellern zu tun. As usual.
Touchpads sind an vielen Mobilgeräten verbreitet. Kompakter als eine Maus, genauer als ein Touchscreen. Wenn es darum geht, wie man diese Bedient, verfolgen verschiedene Hersteller jedoch unterschiedliche Konzepte. Meine bisherigen Laptops nutzten dabei folgende Methode: Zum (links)Klicken drückt man das Pad über den Druckpunkt, für einen Rechtsklick selbes spiel, während zwei Finger auf dem Touchpad sind. Ein neueres Modell mit ELAN-Touchpad fällt hier aus der Reihe: Der „normale“ Klick geht zwar auch über den Druckpunkt, für einen Rechtsklick muss man aber in der unteren, rechten Ecke mit einem Finger über den Druckpunkt kommen. Nervig, wenn man anderes gewohnt ist.
ELAN-Touchpad. Ein Drücken in der rot markierten Ecke löst einen Rechtsklick aus.
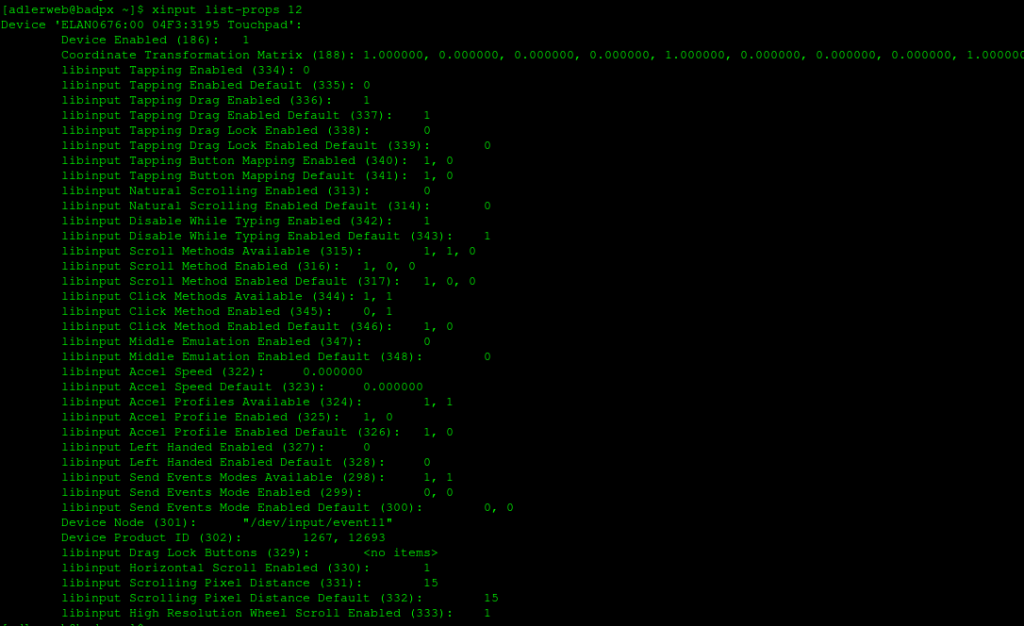
Glücklicherweise kann man unter xorg Abhilfe finden, wenn auch nicht sonderlich dokumentiert. Auf einer Textkonsole in der grafischen Oberfläche kann man mit xinput eine Liste der erkannten Geräte anzeigen lassen. Hier sucht man im Abschnitt Virtual core pointer den Eintrag, welcher das Touchpad sein könnte. Meist kommt dabei das Wort „Touchpad“ im Gerätenamen vor. In der zweiten Spalte findet man eine ID, diese merkt man sich für die nächsten Befehle.
Tipp: Alternativ zur ID kann man für die nächsten Befehle auch den vollen Gerätenamen nutzen. Mit Name ist die z.B. in Scripten weniger anfällig für spontane Neu-Nummerierungen, ist aber mehr Tipparbeit, daher hier mit IDs.
Nun lässt man sich mit xinput list-props 42 die möglichen Einstellungen ausgeben. 42 entspricht hierbei der zuvor ermittelten ID. Interessant sind hierbei unter anderem Folgende Punkte:
Tapping Enabled: Hiermit schaltet man das Tippverhalten um. Im Status 1 muss man zum Klicken das Touchpad nicht mehr über den Druckpunkt drücken, sondern nur den Finger anheben und das Touchpad kurz antippen. Mit zwei Fingern gibt es einen Rechtsklick, mit drei einen Mittelklick.
Tapping Button Mapping Enabled: Hier kann man wählen, ob man das „klassische“ Zwei Finger = Mittlere Maustaste und Drei Finger = Rechte Maustaste oder das heute eher übliche Zwei Finger = Rechte Maustaste und Drei Finger = Mittlere Maustaste nutzen möchte.
Scroll Method Enabled: Hier kann man den Scrollmodus ändern. Meist ist der erste Wert „twofinger“, also Scrollen durch hoch/runter wischen mit zwei Fingern, der Zweite „edge“, also Scrollen durch hoch/runterwischen am rechten Rand und der Dritte button, Also Scrollen durch Wischen bei gedrücktem (mittlerer?) Taste.
Disable While Typing Enabled: Selbsterklärend, oder? Schaltet das Touchpad aus, während man auf der Tastatur tippt.
Click Method Enabled: Hier wird der Modus für das Klicken, also drücken über den Druckpunkt, bestimmt. Der erste Wert bedeutet „buttonareas“, also ein Rechtsklick durch einfaches drücken in der unteren, rechten Ecke. Der zweite Wert steht für „clickfinger“ und schaltet den Rechtsklick über zwei Finger ein.
Liste der Parameter eines ELAN-Touchpads
Um das von mir gewünschte Verhalten erbeizuführen muss also die Klick-Methode geändert werden. Hierbei kann nur eine der Optionen gewählt werden. Der Standard liegt bei „1, 0“, also buttonareas. Ein Ändern auf „0, 1“ bzw. clickfinger ist über folgenden Befehl möglich: xinput set-prop 42 245 0 1 – oder etwas lesbarer mit Geräte– und Optionsnamen xinput set-prop "ELAN0676:00 04F3:3195 Touchpad" 'libinput Click Method Enabled' 0 1.
Die Einstellung gilt dabei nur für die aktuelle X-Sitzung. Sollen diese Dauerhaft sein muss man die Einstellungen entweder über /etc/X11/xorg.conf.d/ vornehmen oder den obigen Befehl in den Autostart des Windowmanagers aufnehmen. Letzteres hat den Vorteil, dass die Einstellung nur für den aktuellen Nutzer gilt und man so unterschiedliche Vorlieben bedienen kann. Ich habe es entsprechend als exec in ~/.config/i3/config gepackt und kann jetzt wieder wie gewohnt rechtsklicken. Oder natürlich einfach ein paar cm weiter oben den roten Nippel nutzen und das Problem nicht haben.
Orrr. Stundenlang gesucht welche Tastenkombination das Touchpad ein und ausschaltet, da es plötzlich unter #Linux auch nach reboots nicht mehr ging. Guess what: Es liegt an der Kernel-Version. Great. Muss ich Heute/Morgen wohl mal ein paar Kirschen pflücken -.-
Den Überblick über sein Lager zu haben ist immer ein aufwändiges, aber notwendiges unterfangen. Was für Elektrobauteile gilt, kann auch für Mehltüten & Co nicht verkehrt sein. Wie viel noch herumliegt hilft dabei Einkäufe besser zu planen und eine Liste was wann abläuft hilft dabei die heimische Schimmelzucht zu verhindern. In diese Lücke schlägt die Software „Grocy“ und verspricht dies und noch viel mehr zu lösen.
Wieder einmal stoße ich an eigentlich einfache Dinge, die dank Closed-Source aber etwas komplizierter sind: Ich möchte Youtube-Videos von meinem Laptop auf dem Fernseher schauen. Hierzu nutze ich üblicherweise einen Chromecast, welcher sich per Chrom[e|ium] oder Smartphone bedienen lässt. Nun hatte ich jedoch den Wunsch nur Bild zu übertragen, den Ton aber am lokal angebundenen Bluetooth-Kopfhöhrer zu behalten. Das ist so leider nicht vorgesehen, also bleibt nur Improvisation.
Für das Bild ist das schnell erledigt: Ein ungenutzter HDMI-Port wird kurzerhand eingeschaltet und per Chrome geteilt, so wird verhindert, dass der Chromecast auf die interne App zurückfällt. Der Ton bleibt so ebenfalls lokal verfügbar, aber nicht Synchron. Durch die Übertragung ist das bild knapp eine Sekunde hinterher.
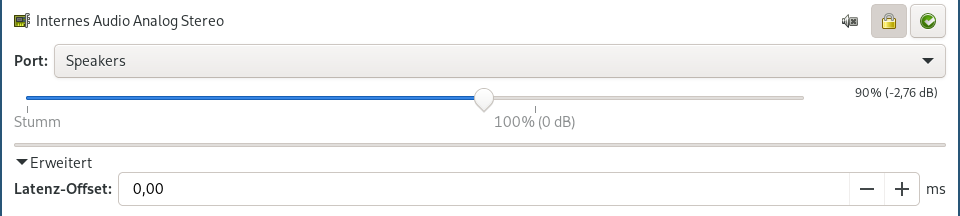
Also muss das Audiosignal des Browsers absichtlich verzögert werden. Pavucontrol bietet hierzu eine Latenzeinstellung, dessen Funktion ist jedoch von der verwendeten Soundhardware abhängig. In meinem Fall konnte ich unabhängig der Einstellung keine Latenz feststellen.
Abhilfe schafft die Konsole und ein Tipp von Thomas auf Stackexchange. Es wird ein Dummy-Gerät registriert, welches vom Browser als Ziel genutzt werden kann. Dieses wiederum wird als loopback wieder an das korrekte Ausgabegerät angehangen. Den passenden Namen der Ausgabe findet man mit pactl list cards. Da hier alles in Software emuliert wird, sind nun die Latenzangaben funktionsfähig.