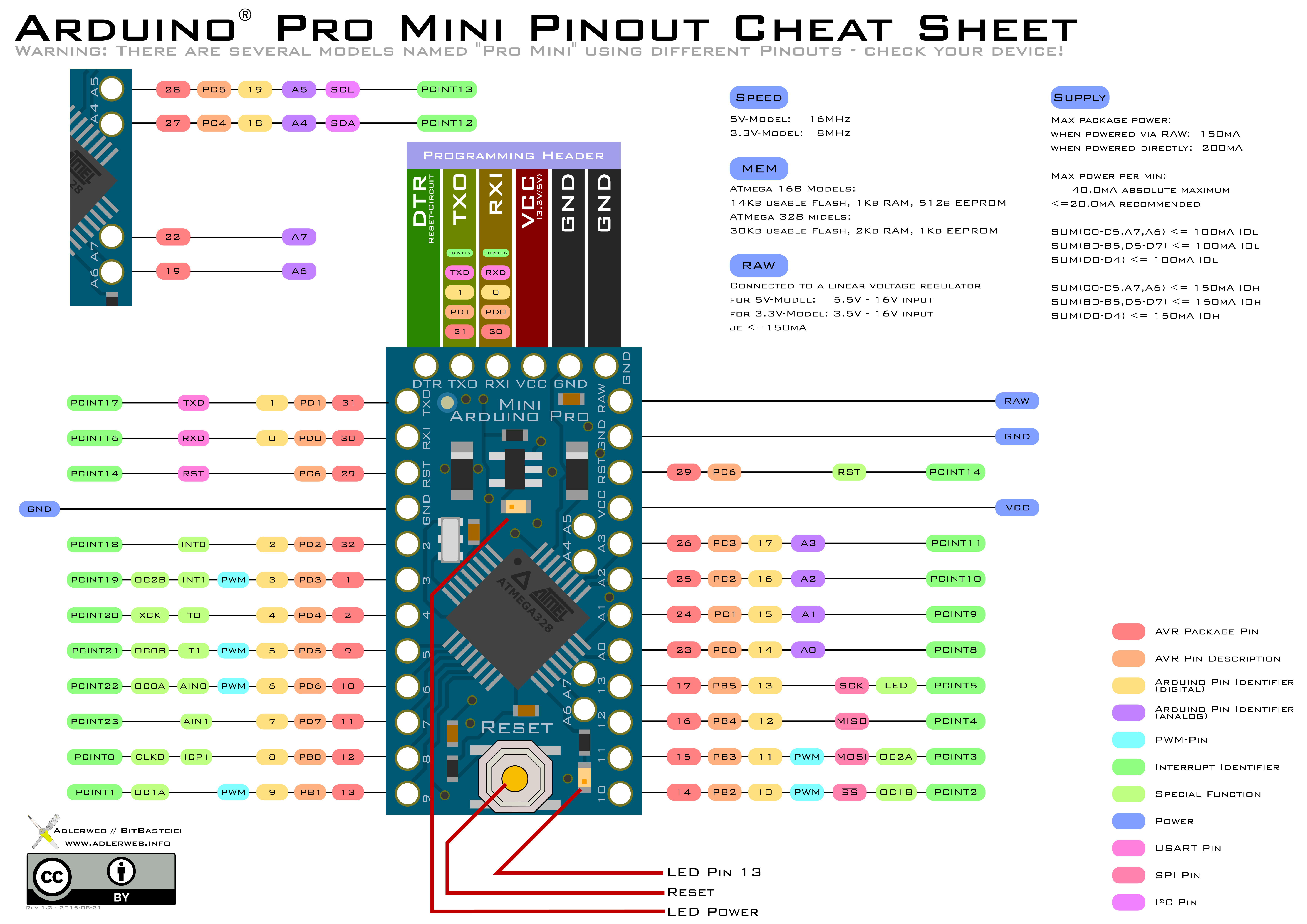
Bisher speicherte ein Windows-System seine Datensicherung per CIFS (aka Samba) auf einer Linux-basierten NAS. Das Konzept ist dabei schon etwas älter – die Windows-Software unterstützte bei der Einrichtung weder Kompression noch Deduplizierung, sodass hier das ZFS-Dateisystem der Linux-Kiste einiges an Platz einsparen konnte. Inzwischen ist die Windows-Software gewachsen: Kompression und Deduplizierung werden bereits vorab durchgeführt, dafür machten die vielen neuen Funktionen immer häufiger Probleme mit CIFS. Kaputte Locks, schlechte Performance, Verbindungsabbrüche – alles lässt sich recht genau auf die Kombination aus dem Server und CIFS zurückführen. Während eine „normale“ Kopie unter Linux mit etwa 100MB/s von statten geht schafft der Server nur 4MB/s. Andere Protokolle sind schneller, andere Windows-Server haben ebenfalls keine Probleme. Inzwischen sind ohnehin neue Platten fällig – Zeit hier gegenzusteuern.
Die Speicherung soll weiterhin auf der Linux-Kiste erfolgen – dort ist die Sicherung und Verwaltung deutlich zuverlässiger und flexibler. Andererseits habe ich keine Lust auf CIFS-Fehlersuche, also lassen wir es einfach weg – die Lösung: iSCSI. Der Windows-Server greift direkt auf den rohen Datenträger des Linux-Systems zu. Da wie erwähnt keine Linux-seitige Kompression stattfinden muss wird diese einfach per LVM verwaltet und ist über den Kernel-iSCSI-Server exportiert. Das Anlegen verläuft ohne Probleme, müssen nur noch die Daten rüben. Mit 4MB/s. Bei fast 4TB. Mit 5 Tagen Restzeit. Nope.
Also, fassen wir nochmal zusammen: Sowohl der alte als auch der neue Datenbestand liegen auf dem selben Linux-System. Warum nicht einfach da kopieren? NTFS-Schreiben unter Linux ist zwar nicht schnell, aber die 4MB/s-Marke sollte zu schaffen sein. Problem: Auf dem LVM-LV hat Windows automatisch eine GPT-Partitionstabelle angelegt, sie lässt sich also nicht direkt unter Linux mounten.
Um trotzdem an das NTFS-System zu kommen müssen wir erst mal wissen wo die passende Partiton beginnt. Hier kommt parted zum Einsatz, welcher auch GPT-Partitionstabellen unterstützt. Da wir die Angaben in Byte, nicht den üblichen Sektoren, benötigen muss die Anzeige erst ungeschaltet werden.
[root@nas ~]# parted /dev/speicher2/windows9
GNU Parted 3.2
/dev/dm-1 wird verwendet
Willkommen zu GNU Parted! Rufen Sie "help" auf, um eine Liste der verfügbaren Befehle zu erhalten.
(parted) unit B
(parted) print
Modell: Linux device-mapper (linear) (dm)
Festplatte /dev/dm-1: 4178147540992B
Sektorgröße (logisch/physisch): 512B/512B
Partitionstabelle: gpt
Disk-Flags:
Nummer Anfang Ende Größe Dateisystem Name Flags
1 17408B 134235135B 134217728B Microsoft reserved partition msftres
2 135266304B 4178146492415B 4178011226112B ntfs Basic data partition msftdata
(parted) quit
Wie wir sehen wurden auf dem LVM-LV durch Windows zwei Partitionen angelegt: Die Erste enthält Managementdaten, die Zweite ist unsere eigentliche NTFS-Datenpartition. Letztere beginnt bei 135266304 Byte – genau diesen Bereich müssen wir auf dem Datenträger also überspringen um auf das NTFS-Dateisystem zugreifen zu können. Also legen wir uns ein passendes Loop-Device an. Da ich bereits ein anderes Device aktiv habe nutze ich loop2 – generell ist die Zahl wählbar.
[root@nas ~]# losetup -o 135266304 /dev/loop2 /dev/speicher2/windows9
[root@nas ~]# mount -t ntfs-3g /dev/loop2 /mnt/test/
[root@nas ~]# mount | grep test
/dev/loop2 on /mnt/test type fuseblk (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other,blksize=4096)
[root@nas ~]# df -h test/
Dateisystem Größe Benutzt Verf. Verw% Eingehängt auf
/dev/loop2 3,8T 604G 3,3T 16% /mnt/test
Passt doch, schon haben wir unter Linux nativen Zugriff auf das Device. Das Kopieren läuft nun mit 90MB/s – nicht ganz die bestmögliche Geschwindigkeit, für NTFS über fuse aber kein Schlechter wert – und etwas schneller als die 4MB/s der Windows-Kiste.

{kind=link}
{kind=link}
{kind=link}
{kind=link}