Vollsicherungen gesamter Festplatten oder Partitionen lassen sich mit dem Unix-Tool „dd“ schnell und einfach anfertigen. Während das Tool automatisiert wohl keine Wünsche offen lässt ist es ein wahrer Quählgeist, wenn man dringend auf die Fertigstellung eines Jobs wartet, denn eine automatische Ausgabe des Fortschirttes ist nicht vorgesehen. Zwar kann man sich hier behelfen, in dem man über den „kill„-Befehl das Signal „SIGUSR1“ an den Prozess sendet und so die Anzeige der verarbeiteten Datenmenge erzwingt, wirklich komfortabel ist dies jedoch nicht.
Senden von SIGUSR1
Bild: https://adlerweb.info/blog/wp-content/uploads/2014/11/pv1-300×98.png
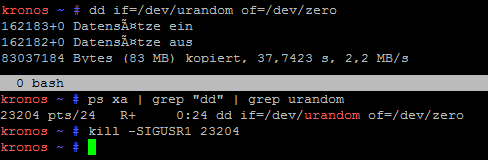
Um das Signal SIGUSR1 an einen Prozess zu senden sollte im ersten Schritt dessen Prozess-ID (PID) ermittelt werden, hierzu kann man in der Ausgabe „ps“ nach dem zuvor gestarteten „dd„-Befehl suchen. Ich nutze zur Suche im Beispiel „grep„. Da zum Zeitpunkt des Schreenshots mehrere „dd„-Prozesse liefen suche ich zudem nach der Quelle des Testjobs (urandom).
kronos ~ # ps xa | grep "dd" | grep urandom
23204 pts/24 R+ 0:24 dd if=/dev/urandom of=/dev/zero
Mit dieser ID kann man nun das Signal über den Befehl „kill“ absetzen. „dd“ verarbeitetet dieses Signal intern, das Programm wird hierdurch nicht beendet.
kronos ~ # kill -SIGUSR1 23204
Während auf der aktuellen Konsole keine Ausgabe erfolgt müsste dd nun einen Status ausgeben, welcher u.A. die verarbeitete Datenmenge sowie die Geschwindigkeit enthält:
162183+0 Datensätze ein
162182+0 Datensätze aus
83037184 Bytes (83 MB) kopiert, 37,7423 s, 2,2 MB/s
Wer sich einen übersichtlicheren und automatisierten Status wünscht kann hier mit dem Zusatztool „pv“ (Pipe Viewer) nachhelfen. Statt die Daten direkt von „dd“ an das Ziel schreiben zu lassen werden sie durch „pv“ geleitet, welches wiederum eine statistische Auswertung anzeigt. Als Ziel kann dann über einen weiteren „dd„-Prozess wieder eine Datei oder Gerät verwendet werden, alternativ gehen natürlich auch Kompressionstools wie „gzip“ oder man lässt die Daten z.B. mittels „nc“ (netcat) oder „SSH“ (Secure Shell) zur Speicherung an einen anderem Rechner senden.
Beispiele mit „pv„
Bild: https://adlerweb.info/blog/wp-content/uploads/2014/11/pv2.png
Daten in Datei speichern
dd if=/dev/lvm/vm-102-disk-1 | pv -pterabs 32g | dd of=vm-102-disk-1.img
15GiB 0:20:34 [ 19MiB/s] [12,5MiB/s] [============================================> ] 46% ETA 0:23:12
Daten über gzip komprimieren und in Datei speichern
dd if=/dev/lvm/vm-102-disk-1 | pv -pterabs 32g | gzip > vm-102-disk-1.img.gz
15GiB 0:20:34 [ 19MiB/s] [12,5MiB/s] [============================================> ] 46% ETA 0:23:12
Daten über gzip komprimieren, per SSH mit schwacher Verschlüsselung an einen anderen Rechner senden und dort in Datei speichern
dd if=/dev/lvm/vm-102-disk-1 | pv -pterabs 32g | gzip | ssh -c arcfour,blowfish-cbc backup@cautio.lan.adlerweb.info 'dd of=/var/backup/vm-102-disk-1.img.gz'
Password:
251MiB 0:00:23 [12,6MiB/s] [10,8MiB/s] [> ] 0% ETA 0:49:38
Wichtig hierbei ist, dass „pv“ am Ende die Größe der Quelldatei/des Quellgerätes genannt wird, in diesem Fall 32 GB. Ingesamt bedeuten die Optionen folgendes:
-p Fortschrittsbalken anzeigen
-t Bisher vergangene Zeit anzeigen
-e ETA, also erwartete Restzeit, anzeigen
-r Aktuelle Datenrate, also „Geschwindigkeit“, anzeigen
-a Durchschnittliche Datenrate anzeigen
-b Bereits kopierte Datenmenge anzeigen
-s Größe der Quelle in Byte, k,m,g,… möglich
Alternative Reihenfolge zum besseren Merken: pertabs (per tabs) oder für Nutzer diverser Imageboards betraps.
Die Ausgabe ist wie folgt zu lesen:
15GiB 0:20:34 [ 19MiB/s] [12,5MiB/s] [====== ] 46% ETA 0:23:12
Kop.Datenmenge|Verg.Zeit|Datenrate|Ø Datenrate | Fortschritt |Restzeit
Damit wäre der nervöse Admin mit beruhigenden Statistiken versorgt und weiß wie lange er sich noch gedulden muss – eine Ausrede weniger die Backups zu vernachlässigen. Natürlich kann „pv“ auch für andere Konstrukte verwendet werden, welche mit einer Pipe arbeiten.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}