Ich bewahre gerne Dinge auf, so auch alte Video- und Bildaufnahmen. Inzwischen wird dies zum Problem, denn Festplatten werden eher teurer als billiger, Datenmengen aber immer größer. Glücklicherweise haben sich aber auch die Formate weiterentwickelt. Moderne Vertreter wie AV1 und OPUS können für Videos mit deutlich kleinerem Speicherbedarf eine gute Qualität liefern. So konnte ich diese Dateien um im Schnitt 96% verkleinern. Eins Fehlt mir aber noch: Bilddateien.
Die Formate
Für Bilder gibt es viele moderne Formate: HEIC kennt man ggf. von Mobiltelefonen und basiert auf H.265 – leider auch mit dessen Lizenzproblemen. Webp stammt von webm ab und ist primär für die Nutzung auf Webseiten entwickelt. Avif wiederum ist das Bild-Pendant zu AV1. Jxl, auch JPEG-XL genannt ist ein direkter Nachfolger des klassischen JPEG-Formates.
Der Test
Zum Testen nutze ich 24 JPEG-Bilder mit insgesamt knapp 60MB. 22 sind Handy-Bilder im Format 4032×3024, die beiden Verbleibenden stammen von älteren Digitalkameras und haben eine etwas geringere Auflösung.
Als Hardware nutze ich einen Server mit 2×E5-2640v4, was 16 Kernen bzw. 32 Threads bei bis zu 2.6GHz entspricht. 192GB RAM und die Speicherung auf NVME sollten kein Bottleneck darstellen
Als Software kommt ffmpeg zum Einsatz. Ausnahme ist heic, dies wird von meiner Version nicht unterstützt, daher muss heif-enc herhalten.
Die Geschwindigkeit
Erste Frage: Wie lange dauert das Umwandeln?
webp 49 Sekunden
jxl 58 Sekunden
heic 68 Sekunden
avif 481 Sekunden
Webp, jxl und heic sind in ähnlichen Bereichen unterwegs und codierten alle Dateien in etwa einer Minute. Avif sticht mit über 8 Minuten klar heraus, ein Umwandeln dauert also deutlich länger.
Die Größe
Der Grund für den ganzen Spaß war ja die Dateigröße. Hier muss man Bedenken, dass die Originalbilder von Digitalkameras und Mobilgeräten stammen, welche eher auf Speichergeschwindigkeit als Effizienz setzen. Bereits beim Recodieren von JPEG zu JPEG sind daher bereits Gewinne zu erwarten. Nicht erwartet habe ich aber das Ergebnis:
original 57.4MiB
jxl 31.1MiB
heic 20.0MiB
webp 11.0MiB
jpeg (recoded) 8.3MiB
avif 5.3MiB
Mit Standardoptionen sind also außer avif alle Formate großer als ein Recodieren mit jpg, welches mit 9s auch ungleich schneller als alle anderen Optionen ist.
Natürlich kann man durch passendes Ändern der Parameter hier noch viel rausholen und vermutlich deutlich andere Ergebnisse erhalten.
Kompatibilität
Das schönste Bild hilft nichts, wenn man es nicht öffnen kann. Linux-User haben hier oft bessere Karten, da der native Support deutlich breiter ausfällt. JPEG und JXL zeigten bei mir die beste Usability, da Thumbnails auch ohne Gebastel direkt erzeugt wurden. Mit der internen Bildvorschau (EOM/EOG) ließen sich alle Dateitypen öffnen. Auch GIMP zeigte sich von der Vielfalt unbeeindruckt.
Qualität
…ist vermutlich eine persönliche Entscheidung. Für meinen Anwendungsfall des „Weglegen-falls-man-es-doch-noch-brauch“ ist quasi alles, was nicht offensichtliche Artefakte zeigt, brauchbar. Ich kann bei AVIF und den Re-Encoded JPEG Abstriche in den Details sehen. AVIF und WebP zeigen eine geringere Sättigung.
Fazit
Tja, nun, nicht ganz, was ich erwartet habe. Besonders enttäuscht hat mich AVIF – eine vielfach längere Umwandlungszeit für massiv schlechtere Qualität hätte ich nicht erwartet. Die neuen Formate brauchen durch die Bank deutlich länger und bringen gegen eine Rekompression in JPEG mir nicht wirklich Vorteile. Wenn man die JPEG-Qualität passend dreht, hat man eine ähnliche Dateigröße und Bildqualität bei einem Bruchteil der benötigten Umwandlungszeit. Für Personen, welche Wert auf hohe Qualität legen oder mit nicht per Kamera erstellten Motiven arbeiten, können neue Formate eine sinnvolle Sache sein, für meinen Zweck scheint aber der über 30 Jahre alte Formatsenior wohl weiter die bessere Wahl.
Wer im Internet schnell zahlen wollte hatte bisher die Auswahl zwischen Kreditkarte für Warenkäufe oder PayPal für Waren und Freunde – beides Dienste aus den USA. Nicht zuletzt wegen den von dort in letzter Zeit immer wieder eintreffenden Drohungen ist diese Abhängigkeit ein massives Risiko für den hiesigen Markt. Eigentlich müsste dringend eine europäische Alternative her, aber was bisher auf den Markt geworfen wurde, ist eher unausgegoren und technisch oft keine gute Idee.
Sofortüberweisung
Eines der ersten Alternativsysteme war der Dienst „Sofortüberweisung“, welcher in Deutschland gegründet wurde und aktuell zur Schwedischen Klarna-Bank gehört. Anders als der Name erwarten lässt, ist es keine direkte Überweisung, stattdessen muss man die Zugangsdaten für sein Bankkonto an den Dienstleister herausgeben. Eigentlich ein sicherheitstechnischer Albtraum, aber leider durch PSD2 erlaubt – selbst ein Gericht urteilte, dass Banken den Kunden nicht verbieten dürften ihre Zugangsdaten an Dritte weiterzugeben. Mit den Zugangsdaten gibt sich der Dienstleister als Kunde aus, loggt sich auf dem Bankkonto ein, lädt die letzten Kontobewegungen und offene Lastschriften herunter und wertet so aus, ob die Zahlung „wahrscheinlich“ funktionieren würde. Ist dem so wird die Überweisung beauftragt und dem Händler direkt bestätigt, dass die Transaktion erfolgreich war. Die Lösung ist mWn eine rein Deutsche Sache und beschränkt sich auf Zahlungen für Waren.
Giropay/iDEAL/…
Etwas besser machten es Systeme wie Paydirekt/Giropay (DE) oder iDEAL (NL). Statt seine Zugangsdaten an Dritte zu geben, wird man hier an seine Bank weitergeleitet. Diese führt die Zahlung aus und bestätigt dem Händler, dass das Geld raus ging. Der Händler bekommt das Geld erst Tage später. Auch hier konzentrierte man sich hauptsächlich auf den Kauf von Waren, mit Kwitt war es aber auch möglich Geld an andere Nutzende zu senden. Soweit mir bekannt aber nur per App, nicht über Webseite o.Ä.. Der große Nachteil: Es setzt nicht auf Stadards und funktioniert daher nur für teilnehmende Banken. iDEAL ist so in DE fast ausschließlich bei Direktbanken wie RaboDirect, bunq, N26, Triodos oder ING verfügbar. Giropay beschränkte sein Geschäft auf Deutschland und war hauptsächlich bei Sparkassen, Volks- und Raiffeisenbanken, der Postbank und Commerzbank verfügbar, wurde jedoch zum Jahresende 2024 eingestellt.
Wero
Ein Europäischer Ansatz ist nun Wero – „We Euro“. Hier sollen Zahlungen an zwischen allen angemeldeten Nutzenden möglich sein. Warenkäufe sollen ab 2026 mit Käuferschutz folgen. Man platziert sich recht direkt als Alternative zu PayPal, jedoch hat Wero wichtige Unterschiede:
Senden ist nur über Handynummer oder E-Mail-Adresse möglich, nicht über einen separaten Benutzernamen
Es können nur Beträge bis 1000€ verwendet werden, je nach Bank sogar weniger
Es gibt eine Liste von Waren, welche mit Wero nicht bezahlt werden dürfen
Für einige Transaktionen ist der Dienst somit von vornherein nicht geeignet. Und für die anderen Fälle trifft man wieder auf ein altbekanntes Problem: Nur für teilnehmende Banken. Wenn sie denn mitmachen, so führte N26 z.B. Wero trotz Ankündigung teilzunehmen bisher gar nicht erst ein, Andere wie Comdirect stiegen gar komplett aus dem Projekt aus.
Hinzu kommt die Bedienbarkeit. Es gibt kein zentrales „Wero“, die Umsetzung ist den Banken überlassen. Dies führt zu einem Wildwuchs von Funktionen und Möglichkeiten. Einige Banken nutzen eine gemeinsame Wero-App. Versucht man diese mit anderen Banken zu nutzen wird man abgewiesen – man solle in der Banking-App schauen. Auch die Berechtigungen sehen unterschiedlich aus – während man teilweise die Handynummern oder E-Mail-Addressen manuell eintippen kann verlangen einige der Banking-Apps für die Nutzung von Wero einen Vollzugriff auf das Adressbuch des Gerätes und verweigern ohne den Dienst.
IMO
Wir brauchen eine europäische Alternative. Schnell. Einheitlich. Flächendeckend. Am Besten getrennt vom für Sicherheit und Benutzerfreundlichkeit eher wenig bekannten Bankensumpf. Wero schafft das in der aktuellen Form nicht. Die technischen Möglichkeiten für „etwas sinnvolles“ sind in meinem Augen an vielen Stellen schon da. Echtzeitüberweisungen (SEPA instant payment) für das Versenden von Geld sind verfügbar und bei allen Banken ab nächstem Monat Pflicht. Anfordern ist noch etwas dünn, da Bankeinzug – wenn auch normiert – fast nur in Deutschland genutzt wird und selbst hier viele Shops diese bisher nicht in Echtzeit an die Banken senden. Der Ansatz ist da, bei der Verbreitung müsste man nacharbeiten. Nach meiner Auffassung sollte ein freies EU-PayPal wie folgt aussehen:
Jeder kann sich registrieren. Registrierte Nutzende können per App, Webseite und API ihre Transaktionen verwalten und Aktionen auslösen. So ist ein breiter Zugriff und Integration in Drittsoftware und Shops einfach möglich.
Der Login nutzt für 2FA freie Lösungen wie TOTP, U2F und/oder WebAuthN/Passkeys. Für das Bestätigen von Transaktionen müsste man sich ggf. noch etwas ausdenken, da mWn keine der verfügbaren Techniken eine Transaktionsbindung beherrscht. Dies sollte aber immer ein freies, quelloffenes Verfahren sein.
Es gibt im Konto übliche Funktionen wie das Blockieren von Kontakten.
Man kann seine Geldquelle über alle gängigen Methoden wie SEPA Instant Payment (mit virtueller IBAN), Debit- und Kreditkarten, Lastschrift & Co verknüpfen – unabhängig davon ob die Bank teilnimmt oder nicht. Durch die breite Unterstützung kann man das System auch nutzen, während rein Europäische Lösungen noch nicht in der Breite verfügbar sind.
Registrierte Nutzer können Geld senden oder anfordern. Als Gegenstelle kann Benutzername, E-Mail, Handynummer oder IBAN (nur senden) genutzt werden. Die Angabe von E-Mails und Handynummern ist dabei immer freiwillig und es lassen ich mehrere Einträge pro Konto verwalten. Ein Senden an EU-IBANs funktioniert auch, wenn die Gegenstelle nicht registriert ist. Zusätzlich kann man permanente oder temporär gültige Links zum Empfangen von Geld generieren, welche den Empfänger festlegen und Optional einen Betrag und Verwendungszweck enthalten.
Wird Geld gesendet, wird die Transaktion erst bestätigt, wenn das Geld erfolgreich eingetroffen ist bzw. die Gegenseite die Transaktion bestätigt hat.
Wird Geld angefordert, muss die Gegenstelle aktiv bestätigen. Man wird über mehrere wählbare Wege (App-Push, EMail, …) über die offene Transaktion informiert. Es gelten bei Annahme dieselben Anforderungen wie beim Senden.
Transaktionen sollten unabhängig vom Zweck für alle legalen Fälle möglich sein. Also z.B. kein generelles Verbot für Transaktionen für den Kauf von Computerspielen ab 18 o.Ä., wie es aktuell bei vielen bestehenden Systemen der Fall ist.
Im Prinzip wäre es in großen Teilen eine andere, zentrale Oberfläche für Funktionen, welche ohnehin schon da sind. Um Anderen Geld zu senden gibt es schon Echtzeitüberweisung – nur ist es umständlich IBAN und ggf. Beträge immer manuell auszutauschen und sich für jede Bank in eine neue UI einarbeiten zu müssen. Ich bin gespannt, ob es irgendwann tatsächlich eine Europäische Alternative geben wird. So lange nicht heißt es für mich wohl leider weiter PayPal-Links weitergeben und hoffen, denn IBAN, EMail oder Handynummern möchte ich nun wirklich keinem diktieren müssen um danach festzustellen, dass deren Bank ohnehin nicht teilnimmt.
(Diese Geschichte hatte ich mWn schon mal gepostet, aber offenbar nie hier im Blog. Ah well.)
Nach einem kleinen Ausrutscher auf einem berüchtigten Auktionshaus hatte ich ein neues Gerät in der Hand, welches $vieldaten machen kann. Um die volle Leistung abzurufen bräuchte es mindestens einen Gigabit-Anschluss. Die Herausforderung: Weit weg von bestehender Infrastruktur. Sicher, die Strecke kann ein langes Patchkabel überbrücken, aber irgendwo knallt ja immer irgendwer die Tür zu – nicht hilfreich für die Lebensdauer einer solchen Wäscheleine.
Netzwerkkabel mit KnotenGequetschte StelleDurch mechanische Beanspruchung weggescheuerte Isolierung
Also einen Tag hingesetzt, eine Rolle halbwegs dünnes Verlegekabel aus dem Lager gegriffen und irgendwie versucht von A nach B zu bekommen. Am Ende ging es über mehrere Kabeltrassen, durch Wände und viel zu überfüllte Rohre zwischen Patchpanel und einer neuen Netzwerkdose. Knapp 28m stand schlussendlich auf dem Zettel. Der Kabeltester bestätigt: Alles Gut.
Moment, was?
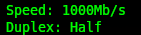
Also: Gerät dran, starten, konfigurieren und … warum hab ich nur 100MBit/s? Seltsam. Also mal schnell die Patchkabel durchgetauscht – immer noch nichts. Laptop dran? Gigabit. Ist das Gerät kaputt? Sollte nicht, aber zur Sicherheit nochmal Gerät direkt an den Laptop und: Gigabit. Laut anzeige zwar Half Duplex, aber das verbuche ich mal unter „Anzeigefehler“.
PC meldet 1G Half DuplexGerät meldet Fast Ethernet (100MBit/s)
Fassen wir zusammen: Meine Strecke ist laut Kabeltest OK, mit dem Laptop bekomme ich Gigabit, mit dem Gerät aber nur 100MBit/s. Das Gerät scheint aber auch keine Fehlfunktion zu haben und funktioniert direkt mit dem Laptop verbunden fehlerfrei.
Ich hasse dieses Kupferzeugs -.-
Auf die Suche
So komm ich nicht weiter, also ein besseres Messgerät geliehen, ich nenne es liebevoll „Dienstleisterfolterapparat“, denn neben Durchmessen der einzelnen Leitungen prüft dieses auch auf Dämpfung, Übersprechen & Co – also Alles das, was knallt, wenn irgendwo Irgendwer eine Leitung zwischendrin nicht fachgerecht „repariert“ oder behandelt hat. Nein, Isoband eigent sich nicht um ein versehentlich durchgeschnittenes Netzwerkkabel wieder zu richten. Und siehe da: Die Signalqualität auf dem Paar 3+6 passt nicht.
Mögliche GeschwindigkeitenErgebnis des TestsFeldermeldung „Verteilte Kabelfehler“
OK, nicht gut. Und solche Fehler lassen sich leider – im Gegensatz zu Kurzschlüssen oder falsch geklemmten Leitern – auch nicht sinnvoll lokalisieren. Aber vielleicht hab ich ja irgendwo einen Fehler an den Enden gemacht. Also: Ab mit den Dosen, Neue drauf. Nope, weiter 3+6. Stochern wir mal rum, denn die Paare 3+6 und 1+2 sind je nach genutztem Farbkonzept miteinander getauscht. Technisch irrelevent, so lange man beide Seiten gleich macht, aber wenn wir die tauschen … jepp, der Fehler wandert und ist nun auf 1+2. Ich kann also sehr sicher sagen, dass das in diesem Fall grüne Adernpaar einen Fehler hat. Mist.
Ergebnis des Tests. Signalfehler auf Paar 1+2
Vollkabeleingrenzung
Das Kabel ist also kaputt. Eventuell zu stark dran gezogen? Was geknickt? Hilft alles nichts, die Strecke ist für die Tonne. Oder zumindest etwas. Auf halber Strecke liegt eine gut zugängliche Stelle, von der aus es jeweils in viel zu überfüllten Kabelführungen verschwindet. Zum Verteiler kann man mit etwas Angeln vielleicht noch was werfen, zur Endgerät bin ich mir nicht sicher, ob die bröckelnden Leerrohre einen Kabeltausch noch überleben. Augen zu, durchgeknipst und in Richtung Verteiler eine Buchse draufgesetzt.
Keystone-Buchse auf KabelendeErgebnis des Tests
Bingo! Da ist der Fehler! Ärgerlich, aber machbar. Wobei es mich ehrlich gesagt wundert, denn die Rolle stand beim Zeihen am Verteiler, diese Strecke wurde also am wenigsten Belastet. Aber immerhin heißt das ja, dass die andere Richtung OK ist. Oder? ODER?
Ergebnis des Tests
Was zum.
Zwei Richtungen, beide Fehlerhaft. Langsam Zweifel ich an meinem Verstand. Zur Sicherheit mal eine andere Strecke im Gebäude gemessen – ja, das Messgerät kann auch Haken verteilen. Also muss da wirklich was kaputt sein. Aber wie? Einen Kabelbruch lass ich mir ja gefallen, aber zwei? Je auf dem gleichen Aderpaar? Während die Anderen jeweils nicht betroffen sind? I doubt it.
Die Rolle steht noch am Verteiler, also werfen wir mal einen Blick auf das Etikett.
Kabel auf RolleBeschriftungen auf Rolle
CAT6. S/FTP. PiMF. Soweit gut. Das CCA macht zwar ein paar Falten auf der Stirn, aber auf so kurzer Strecke? Meh, sollte trotzdem funktionieren. Andererseits gehen mir auch die Ideen aus. Schnell den Rest von der Rolle geschnappt und einfach mal Buchsen drauf – außer Abrollen hat das also keine mechanische Belastung gesehen. WOLLT IHR MICH VERSCHEIẞERN? Auch das frische Stück Kabel direkt von der Rolle hat auf dem selben Aderpaar einen Fehler.
Ob das jetzt ein Herstellfehler oder Altersschwäche ist kann ich nicht mehr nachvollziehen. Die Rolle lag knapp 6 Jahre in der Ecke. Vermutlich ist es mir bisher nicht aufgefallen, da ich diese nur für Steuerungen genutzt habe, die weniger Anspruchsvoll sind. Tatsächlich habe ich beim Prüfen der Logs aber feststellen können, dass eine 1-Wire-Strecke mit diesem Kabel gebaut wurde, welche tatsächlich schon in der Vergangenheit durch hohe Fehlerraten auffällig geworden ist. Da die Anlage in der Nähe von elektrischen Großverbrauchern ist, hatte ich die Fehler immer darauf geschoben, aber es ist tatsächlich auch bei der installation genau dieses Aderpaar betroffen.
Nun darf ich also die komplette Strecke einmal neu ziehen. Oder es zumindest versuchen. Diesmal wird die Rolle aber vorab getestet, denn offenbar kann man sich nicht mal drauf verlassen, dass ein Kabel funktionsfähig auf einer Rolle ist.
Wer diese Nachricht sieht hat meist etwas Arbeit vor sich. Aber was, wenn der Speicher eigentlich gar nicht so voll sein sollte? Nun, dann muss man auf die Jagd gehen.
Vorab: Ich werde mich hier auf Befehle für die Kommandozeile beschränken, da sich diese sowohl auf Desktop-Rechnern mit GUI als auch Servern nutzen lassen. Auch gehe ich von einem „einfachen“ Dateisystem ohne Kompression, Snapshots oder Subvolumes aus.
Fall 1: Es ist voll – Belegung analysieren.
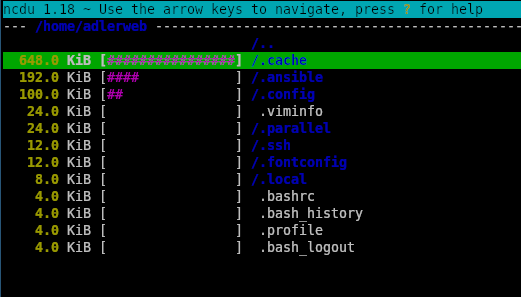
Die einfachste Variante: Irgendwas belegt tatsächlich den Platz. Dies ist der Fall, wenn die Ausgabe von du -shx / bzw. du -shx /dein/ordner tatsächlich etwa dem „Used“-Wert aus df -h / bzw. df -h /dein/ordner entspricht.
Für diesen Fall gibt es viele Tools, welche bei der Analyse helfen können, z.B. ncdu, welches sich in fast allen Paket-Managern finden sollte. Mit ncdu -x / bzw. ncdu -x /dein/ordner ermittelt es die Dateigrößen und stellt diese in einer TUI dar. Über die Pfeiltasten kann man zwischen den Dateien und Ordnern wechseln, mit Enter kommt man in den Order bzw. bei .. wieder zurück und mit d kann man die Datei direkt löschen.
Fall 2: Es ist noch voll – Gelöschte Dateien
Wenn der Usage-Wert aus df größer als jener aus du ist, dann können gelöschte Dateien im Spiel sein. Zumindest, wenn diese noch geöffnet ist. Nehmen wir ein Beispiel: Wir haben eine 4GB ISO-Datei im Ordner, diese binden wir in eine VM ein. Etwas später stellen wir Fest, dass wir die Datei ja eigentlich nicht mehr brauchen und löschen sie aus dem Ordner. Nun sollte man erwarten, dass im Ordner wieder 4GB frei sind, oder? Sind sie nicht, denn wir haben die ISO ja noch in der VM eingebunden, daher hat Linux nur vorgemerkt, dass die Datei gelöscht werden soll, gibt den Speicher aber erst wieder frei, wenn diese nirgendwo mehr in Verwendung ist. Ähnliches kann auch beim Überschreiben auftreten, da Linux die vorherige Version verfügbar hält, so lange diese von einem Prozess genutzt wird.
Die einfachste Möglichkeit solche Situationen zu beheben ist der Holzhammer: Ein Reboot beendet alle Prozesse, entsprechend ist auch nichts mehr geöffnet und alles Markierte verschwindet tatsächlich. Wer etwas feinfühliger sein möchte kann schauen, welcher Prozess derzeit bereits gelöschte Dateien verwendet. Die volle Liste gibt es mit . Etwas übersichtlicher macht es der Befehl *lufthol*
Dieser Zeigt jede gelöschte, aber noch geöffnete Datei 1×, die Größten finden sich ganz oben in der Ausgabe. Hier sind ggf. auch andere Speicherbereiche wie memfs oder /dev/shm/… mit aufgelistet, welche für die Dateisysteme nicht relevant sind.
Hier hat z.B. ein qemu-Prozess mit der PID 32387 einen für uns nicht relevanten memfd mit 32 Gigabyte. Ein systemd-Teil mit der PID 2448 hält wiederum 13MB durch die Datei /usr/lib/udev/hwdb.bin in Beschlag, welche zwischenzeitlich überschrieben wurden. Mit diesen Informationen kann man die zugehörige Software dann gezielt beenden bzw. neu starten um den Speicher wieder freizugeben.
Fall 3: Es ist doch voll – Mount in vollem Ordner
Ein etwas anderer Fall, bei dem sich df und du unterscheiden, kann auftreten, wenn man mit mehreren Partitionen oder Datenträgern arbeitet. Auch hier wieder ein Beispiel: Wir haben eine Festplatte mit installiertem Linux. Unter /mnt/iso/ speichern wir jetzt 5 verschiedene Linux-ISOs mit je ca. 2GB, belegen also 10GB. Nun merken wir, dass wir mehr Platz benötigen, bereiten eine zusätzliche Festplatte vor und hängen diese unter /mnt/iso/ ein. Nun sind die ursprünglichen Dateien ja noch unter /mnt/iso/ gespeichert, da dort aber ein anderes Dateisystem eingehangen ist, wird der Pfad bei du (oder auch ncdu) ignoriert. Ähnliches habe ich auch häufiger bei der Verwendung mäßig stabiler Software wie Docker entdeckt – dies „vergisst“ bei einigen Container-Neustarts einige mounts mitzunehmen und schreibt die Daten dann nicht auf die Datenpartition, sondern, für das Hostsystem erst mal unsichtbar, auf den Datenspeicher des Root-Dateisystems. Um dies zu analysieren verwende ich gerne einen bind-mount, diese nehmen keine anderen Dateisysteme mit und schaffen so eine Stelle, um mit ncdu das komplette Dateisystem zu erfassen.
mkdir /tmp/bind
mount -o bind / /tmp/bind
ncdu -x /tmp/bind
# Nachdem man fertig ist
umount /tmp/bind
rmdir /tmp/bind
Fall 4: Es ist voll kaputt – Dateisystemfehler
Natürlich kann es auch immer mal vorkommen, dass das Dateisystem tatsächlich einen Fehler hat und daher den freien Speicher falsch berechnet. Hier hilft dann oft (vorzugsweise von einem Live-System) die jeweiligen Scan- und Reparaturtools zu starten. Meist sollte ein fsck /dev/yourdevice das passende Programm auswählen.
Hat man Windows vor $langerzeit installiert, wird das System vermutlich einen MBR und BIOS-Boot nutzen. Auch wenn diese Methode meist noch funktioniert, ist sie doch nicht mehr ganz zeitgemäß und kann in einigen Situationen dazu führen, dass man plötzlich etwas Bootfunktionalität vermisst. Insbesondere mit virtuellen Systemen, oder bei Dual-Boot, ist EFI oft flexibler und GPT im Zweifel resilienter gegen Störungen. Glücklicherweise kann man solche Systeme oft mit ein paar Befehlen, etwas Geduld und vielen gedrückten Daumen erfolgreich umwandeln, ohne dass eine Neuinstallation oder größere Kopiervorgänge notwendig sind.
Vorbedingungen
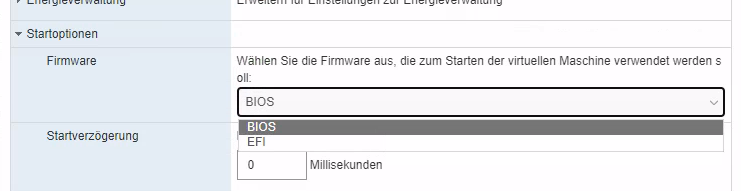
Um erfolgreich auf das GPT-Partitionsschema und einen EFI-Bootloader umzustellen, müssen einige Vorbedingungen erfüllt sein. Zuallererst muss die drunterliegende Hardware bzw. der Hypervisor natürlich das Booten per EFI unterstützen. Für Hardware sollte alles aus den letzten 10+ Jahren funktionieren. Bei VMs muss ggf. in der Konfiguration der Boot-Modus umgestellt werden.
Screenshot VMWare, VM-Optionen. Startoptionen→Firmware mit der Auswahl zwischen BIOS und EFI
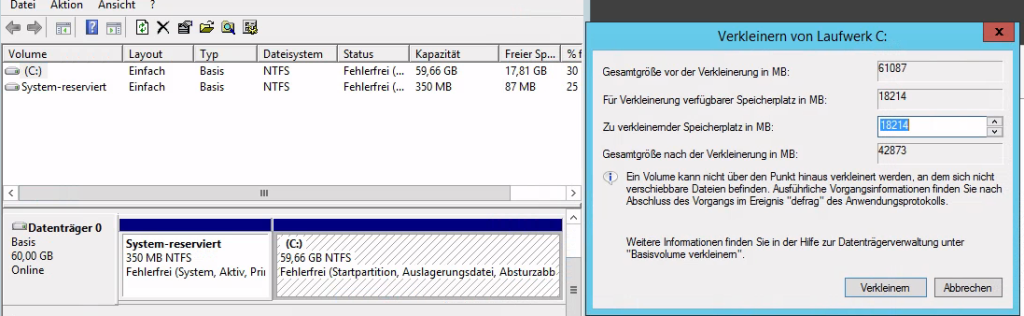
Weiterhin wird etwas Platz benötigt. Etwa 150MB reichen aus. Bei VMs kann man z.B. die virtuelle Festplatte vergrößern, andernfalls kann man in Windows die Datenträgerverwaltung bemühen und die letzte Partition des Datenträgers verkleinern. Für Profis: Zumindest ein paar Byte müssen am ENDE des Datenträgers frei sein.
Screenshot Windows Datenträgerverwaltung. 60GB Datenträger mit 350MB NTFS System-reserviert und 59.66GB NTFS C:. Daneben Dialog „Verkleinern von Laufwerk C:“ mit Vorschlag um 18214MB zu verkleinern.
Verschlüsselungen wie Bitlocker habe ich nicht genutzt, im Zweifel sollte man diese für die Dauer der Umstellung abschalten. Ein Boot-Stick des Betriebssystem (bei aktuellen Systemen als Download, teils über Media Creation Tool) sollte zur Hand sein. Ich nutze Ventoy mit den zugehörigen ISOs.
Zu guter Letzt sollte man natürlich ein getestetes(!) Backup besitzen. Auch wenn die Methode bei mir bisher zuverlässig funktionierte, kann immer etwas schief gehen. Jedes System ist anders.
Part 1: Partitionsschema umwandeln
Erster Schritt ist die Umwandlung von MBR zu GPT. Letzteres ist deutlich neuer, hat Mechanismen um Beschädigungen zu erkennen/reparieren, kann mit größeren Datenträgern umgehen (MBR max. 2TB) und kann mehr als 4 (primäre) Partitionen pro Datenträger verwalten. Um keine Konflikte mit dem eigentlichen System zu provozieren nutze ich ein Linux-Livesystem, namentlich GParted. Technisch sollte auch das Windows-Tool mbr2gpt.exe funktionieren, dieses hat jedoch einige Einschränkungen.
Als Erstes startet man also GParted. Die Standardeinstellungen sind meist OK, bestenfalls das Tastaturlayout sollte man auf QWERTZ ändern, falls man mit QWERTY nicht klar kommt. Die GUI kann direkt über den „Block“ oben rechts geschlossen werden, stattdessen benötigen wir das Terminal. Hier macht man sich über „sudo su“ zum Systemverwalter. Wir wissen ja was wir tun und haben ein Backup – oder so. Mit lsblk kann man die aktuellen Datenträger und Partitionen raussuchen. Hier notiert man sich den Namen der Festplatte/SSD (Type: disk), welche man umwandeln möchte. Für S-ATA ist dies meist „sda„, bei NVME „nvme0n1„.
Nun geht es an die eigentliche Umwandlung. Mit „gdisk /dev/sda“ (name passend Tauschen) öffnet man das Gerät im GPT-Editor. Dieser sollte nun energisch darauf Hinweisen, dass er Magie anwendet und keine Gewähr für fehlende Körperteile oder Daten übernimmt:
Found invalid GPT and valid MBR; converting MBR to GPT format in memory. THIS OPERATION IS POTENTIALLY DESTRUCTIVE! Exit by typing 'q' if you don't want to convert your MBR partitions to GPT format!
Wichtig: Es darf keine Warnung bzgl. überlappenden Partitionen geben.
Warning! Secondary partition table overlaps the last partition by 33 blocks!
You will need to delete this partition or resize it in another utility.
Ist dies der Fall, steht am Ende des Datenträgers nicht genug Speicher zur Verfügung, es wurde also wohl nicht, wie oben beschrieben, passend verkleinert. Eventuell kann man in diesem Fall über die GParted-GUI die dortige Partition nochmal verkleinern bzw. verschieben und es erneut versuchen.
Alles OK? Dann haben wir nichts weiter zu tun. Gdisk hat bereits alle MBR-Partitionen in das GPT-Equivalent umgerechnet. Wer möchte kann mit „p“ einen Blick drauf werfen. Mit „w“ wird – nach Bestätigung – die neue Partitionstabelle auf den Datenträger geschrieben. Der GPT-Part ist somit abgeschlossen.
Part 2: EFI-Boot
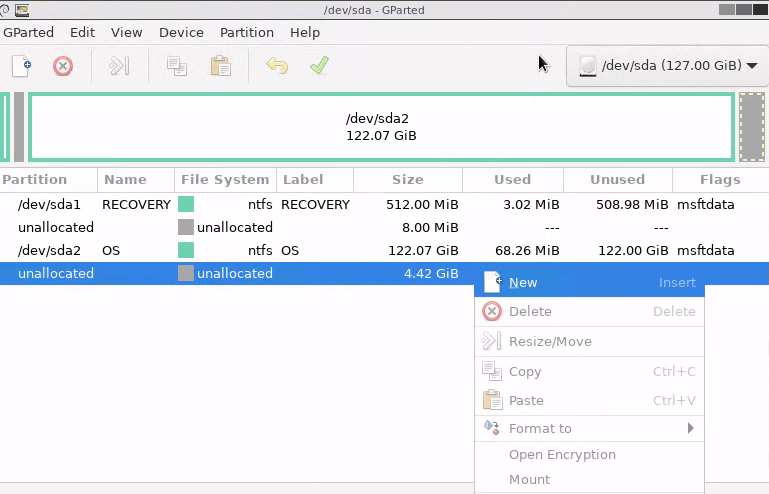
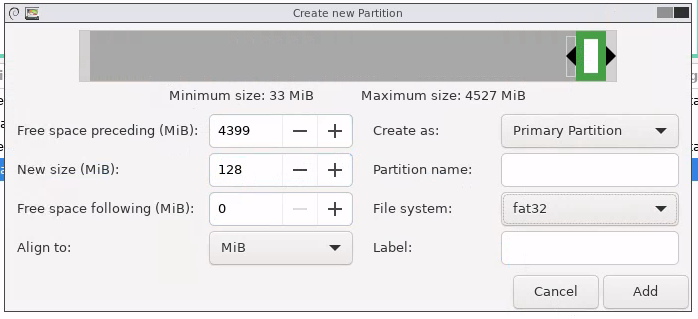
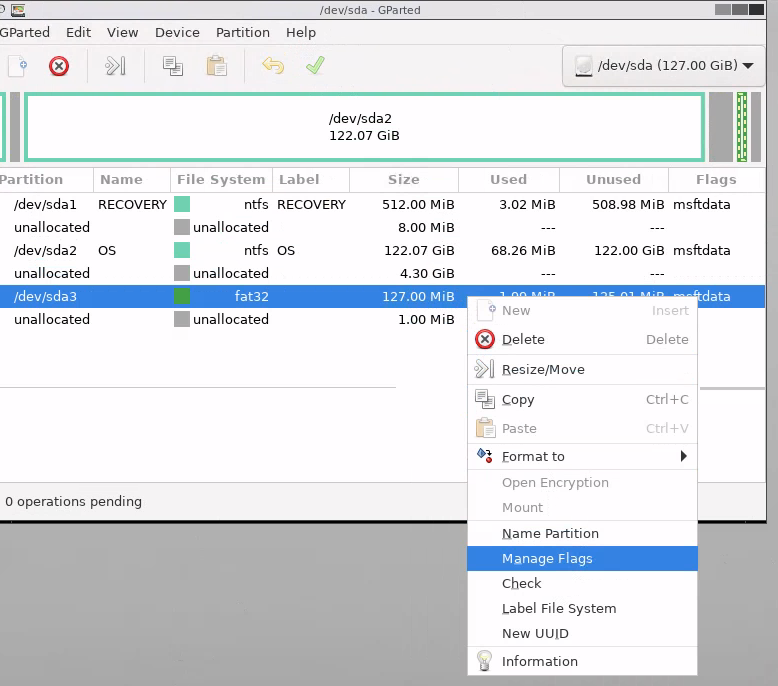
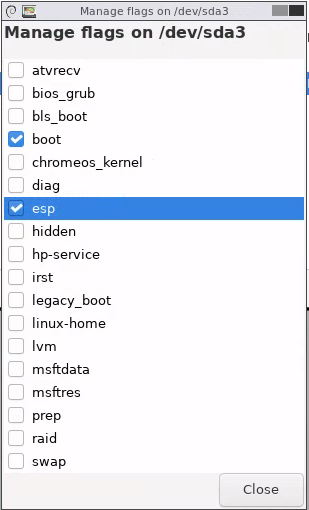
Für UEFI benötigen wir jedoch noch etwas: Eine spezielle Boot-Partition. Diese ist vom Typ FAT32 und sollte >=100MB groß sein. Ich nutze für Umstellungen meist 128MB, Standard für Neusysteme ist bei den meisten Betriebssystemen etwa 512MB. Da GParted noch gebootet ist, kann man diese z.B. über die GParted-GUI an einer freien Stelle passend anlegen – ist meist übersichtlicher als auf der Konsole freie Blöcke zu finden. Windows lässt gerne mal ein paar Sektoren zwischendrin frei und verwirrt die Automatiken von fdisk & co. Also: In der GUI einen freien Block suchen, Rechtsklick→New, ggf. bei „New Size“ die gewünschte Größe anpassen und als File System „FAT32“ wählen. Ich schiebe die Partition meist noch oben nach rechts und vergrößere die Partition des Betriebssystems um eventuelle Lücken zu füllen. Über den grünen Haken schreibt man die Änderungen auf den Datenträger. Nach Abschluss des Vorgangs muss die Partition noch als „EFI System Partition“ markiert werden. Dazu macht man einen Rechtsklick auf die frische FAT32-Partition und wählt unter „Manage Flags“ die Einträge „esp“ und „boot„. Der Datenträger ist somit für EFI vorbereitet und GParted kann heruntergefahren werden.
Screenshot GParted, Datenträger sda mit 127GiB. sda1; RECOVERY, ntfs; 3.02/512MiB – 8Mib unallocated – sda2; OS; ntfs; 68.26MiB/122.07MiB – 4.42GiB unallocated (ausgewählt). Kontextmenü mit „New“ ausgewählt.Screenshot „Create new Partition“. Schmaler Kasten rechts im Balken. Free space preceding: 4399MiB, New Size 128MiB, Free space Following: 0MiB, Aligned to MiB, Create as Primary Partition, File System fat32. Kein Name/Label. Screenshot gparted mit neuer fat32-Partition und 1MiB unallocated dahinter. Kontextmenü der Partition. Manage Flags ausgewählt.Dialog „Manage Flags“. boot und esp ausgewählt.
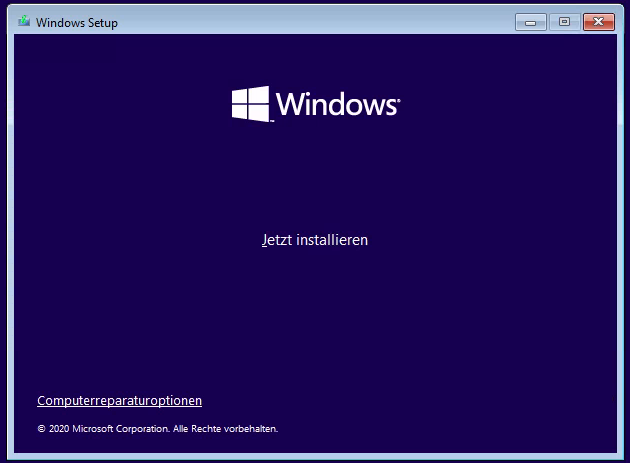
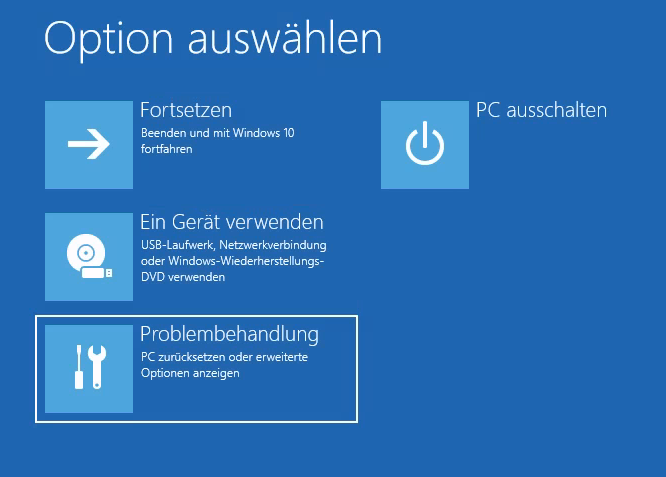
Jetzt muss nur noch das Betriebssystem überzeugt werden mit der neuen Basis zu starten. Hierzu startet man einen passenden Installationsdatenträger, wählt aber über Repair→Troubleshoot die Eingabeaufforderung/Command line.
Windows 10 Setup Begrüßungsbildschirm. In der Mitte „Jetzt installieren“, unten links „Computerreparaturoptionen“.Optionsauswahl für Reparatur. Fortsetzen, Ein Gerät verwenden, Problembehandlung und PC ausschalten. Problembehandlung ausgewählt.Erweiterte Optinen. Starthilfe, Eingabeaufforderung (ausgewählt), Updates deinstallieren, UEFI-Firmwareeinstellungen, System wiederherstellen, Systemimage-Wiederherstellung
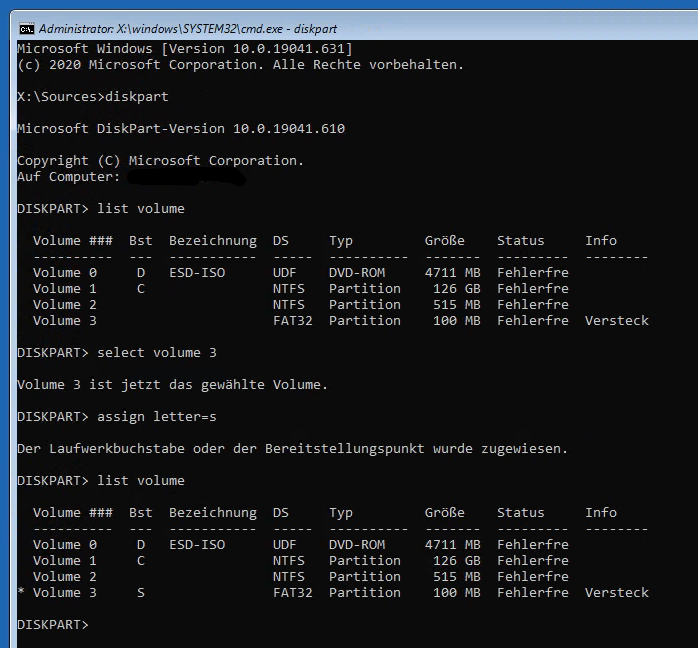
Hier werden dann erst mal die Laufwerksbuchstaben sortiert – ist mir sonst zu viel Chaos. Mit diskpart gelangt man in den passenden Editor, mit list volume kann man die aktuellen Partitionen und deren Buchstaben anzeigen lassen. Möchte man etwas ändern, wählt man z.B. mit „select partiton 3“ aus und weist mit „assign letter=s“ den Buchstaben zu. Ich habe die Windows-Partition auf C und die kleine EFI-Partition auf S.
Screenshot Eingabeaufforderung mit Diskpart. list Volumes zeigt die zuvor genannten Partitionen sowie die DVD (D). Die OS-Partition hat den Buchstaben C, die EFI-Partition hat keinen Buchstaben. Nach select volume und assign letter zeigt list volume den buchstaben an.
Ist man Fertig kann man das Tool mit exit beenden. Zuletzt wird der Windows-Bootloader neu aufgebaut – dies geschieht über die folgenden Befehle:
Nun kann man mit Exit und den passenden Menüpunkten das System ausschalten. Mit ausreichend gedrückten Daumen sollte beim nächsten Versuch Windows dann wieder starten und das gewohnte System präsentieren. Dieses kann man nun bewundern und die durch Umwandlung statt Neuinstallation gewonnene Zeit nutzen um darüber nachzudenken, wie man die Anwendung zukünftig auf ein freies Betriebssystem umziehen kann.
GitLab ist – wie der Name schon erahnen lässt – ein Git-basiertes Entwicklungsmanagement auf Ruby-Basis. Zusätzlich zur Versionsverwaltung gibt es auch Issue-Tracker, Wikis, CI/CD und Vieles mehr. Im Gegensatz zu GitHub lässt es sich auch lokal auf eigenen Systemen installieren, in der Community Edition dabei unter freier Lizenz. Als Alternative wäre noch Forgejo zu nennen, welches weniger kommerziell daher kommt.
Auf einer GitLab-Instanz hatte ich nun eine etwas andere Aufgabe: Ein verwendeter Zugang wurde als potentiell unsicher eingestuft. Nichts, was eine direkte Aktion notwendig machte, aber man sollte es auch nicht ignorieren. Normalerweise erzwinge ich in solchen Fällen einen Passwortwechsel beim nächsten Login. So wird der Nutzer zu geeigneter Zeit aktiv auf das Problem hingewiesen und es sind keine alternativen Kommunikationskanäle notwendig. Während GitLab prinzipiell einen erzwungenen Passwortwechsel unterstützt, gibt es offenbar keine Option dies über die üblichen Wege manuell auszulösen.
Der offizielle Weg
Die Offizielle Empfehlung ist recht klar: Als Admin unter Overview→User→Edit und dort ein neues Passwort festlegen. Dies ist temporär, der User muss es beim nächsten Login ändern. Hierbei wird auch sichergestellt, dass die aktuellen Kennwortrichtlinien eingehalten werden.
Für mich in diesem Fall kein sinnvoller Weg, da durch den Kennwort-Wechsel der Zugang umgehend nicht mehr möglich ist und ein separater, sicherer Kommunikationskanal notwendig ist um das neue, temporäre Kennwort zu übermitteln.
Eingeweide
Offiziell geht es also nicht, aber die Funktion selbst ist ja da. Über einige Tricks kann man dafür sorgen, dass der Passwortwechsel mit dem aktuellen Kennwort angefordert wird. Notwendig ist dazu ein Konsolenzugang zum Server, auf dem GitLab ausgeführt wird. Hier startet man eine Rails-Konsole (ggf. mit sudo), sucht den User und setzt das Ablaufdatum des Kennworts auf die aktuelle Zeit.
gitlab-rails console
user = User.find_by_username('bernd')
user.password_expires_at=Time.now
user.save
quit
Beim nächsten Login sollte nun der Passwortwechsel angefordert werden. Tipp: Es gibt auch ein verlockendes user.password_automatically_set. Dieses sorgt nicht für einen Passwortwechsel, sondern sperrt den interaktiven Login vollständig.
Eigentlich schade, dass so eine einfache und technisch vorhandene Möglichkeit nicht in den Dialogen angeboten wird. Auch wenn ich sicherheitstechnisch nachvollziehen kann, dass eine Sperrung und temporäres Passwort oft die bessere Wahl ist, sollte man den Admins nicht die Wahl vorenthalten Prozesse zu nutzen, welche den eigenen Anforderungen bessern entsprechen.
Im Kreis Mayen-Koblenz sind viele Glascontainer seit mehr als einem Monat überfüllt. Wilde Müllablagerungen an Containern und in Waldgebieten nehmen zu.
Glassammelstelle Andernach Güterbahnhof. Alle Container mit Flaschen zugestellt
Leere Glascontainer sind Mangelware
Überfüllte Glascontainer im Kreis Mayen-Koblenz sind seit geraumer Zeit ein Ärgernis. Wer sein Glas entsorgen möchte, steht vor einem Dilemma: Die so genannten „Iglus“ sind randvoll, einfach das Glas auf den Container oder in der Nähe abstellen würde aber eine Ordnungswidrigkeit darstellen, die mit einer Strafe von mehr als 100€ geahndet werden kann. Bürger*innen haben nur zwei Optionen: Weiter suchen, in der Hoffnung einen leeren Container zu finden, oder das Glas zum Wertstoffhof des Abfallzweckverbandes bringen, welcher jedoch sehr abgelegen liegt und nicht für eine Anlieferung ohne PKW ausgelegt ist.
Glassammelstelle Andernach Wasserturm. Container mit Tüten und Kartons voller Flaschen umstellt.
Das Unternehmen hinter den Containern
Zuständig für die Sammlung der Glas-Verpackungsabfälle im Kreisgebiet ist das Unternehmen PreZero. Dieses ist Teil der Schwarz-Gruppe, welche durch die Marken Lidl und Kaufland bekannt ist. Die Sammlung von Verpackungsabfällen ist in Deutschland durch das Verpackungsgesetz im „Dualen System“ geregelt und wird von der Privatwirtschaft selbst organisiert. Die Vertragsgebiete richten sich zwar oft nach den Stadt- oder Kreisgrenzen, die Kommunen selbst haben in der Auftragsvergabe allerdings keinen direkten Einfluss.
Glassammelstelle Saffig Sportplatz. Einzelne Flaschen auf dem Container.
Richtiges Entsorgen
Wie im letzten Abschnitt erläutert, sind die Container nur für Glasverpackungen vorgesehen, also Gegenstände aus Glas, die dazu dienten, Produkte zu verpacken. Entsprechend darf nicht jedes Glas in die Container geworfen werden. Zu Verpackungen gehören Glasflaschen von Joghurt & Co, Getränkeflaschen und die zugehörigen Deckel, nicht aber andere Glasprodukte wie Geschirr, Blumenvasen, Fensterscheiben, Glühbirnen oder Trinkgläser. Alles, was keine Verpackung ist, muss immer zu den Sammelstellen gebracht werden, teils ist auch eine Entsorgung über den Rest- oder Sperrmüll möglich. Pfandflaschen sollten natürlich ebenfalls nicht in die Glascontainer geworfen werden. Eine Übersicht über erlaubte und verbotene Abfälle liefert zum Beispiel die Trenntabelle der Initiative „Mülltrennung wirkt“, welcher durch einen Zusammenschluss verschiedener Recycling-Firmen ins Leben gerufen wurde. Ähnliche Einschränkungen gelten im Übrigen auch für den Gelben Sack bzw. zukünftig die Gelbe Tonne, welche ebenfalls nur für Verpackungen genutzt werden darf und im Kreis dem selben Unternehmen zugeteilt wurde.
Glassammelstelle Andernach Sportanlagen. Alle Container mit Flaschen, Tüten und Sperrmüll zugestellt.
PreZero: Defektes Fahrzeug verhindert Abfuhr
PreZero ist sich der Probleme bewusst und gibt auf Rückfrage an, dass aufgrund regionaler Besonderheiten ein Spezialfahrzeug für die Leerung der Container notwendig sei. Dieses befinde sich derzeit in Reparatur, sodass man improvisieren müsse. Es wird erwartet, dass das Fahrzeug in dieser Woche wieder einsatzbereit sei. In der Zwischenzeit improvisiere das Unternehmen und würde täglich mit Sammelteams die Umgebung überfüllter Container säubern. Bürger*innen werden gebeten, die vollen Container zu meiden und Verständnis für die vorübergehenden Unannehmlichkeiten aufzubringen.
Glassammelstelle Miesenheim Nettehalle. Flaschen auf dem Container, Tüten vor dem Container.
Eigene Meinung
Die Probleme mit den Glascontainern sind für alle Anwohnenden frustrierend. Bei mir stapeln sich die Gläser, wild entsorgte Reste haben mir durch ihre Scherben schon den ein oder anderen Radreifen vermackt und wer in der Nähe wohnt hat neben dem Anblick auch mit dem zugehörigen Geruch zu kämpfen. Immerhin ist dem zuständigen Unternehmen die Situation bekannt und eine Besserung angekündigt. Bedenklich finde ich, dass durch das Fahrzeug offenbar ein einzelner Ausfallpunkt besteht und man keine Reserven hat bei Defekten die Abfallentsorgung aufrecht zu halten. Auch hätte ich mir eine proaktivere Kommunikation der zuständigen Stellen gewünscht, wenn das Problem über so lange Zeiträume auftritt.
Glassammelstelle Andernach Netto. Viele Scherben und Tütenreste vor dem Container. Am Tag zuvor war der Platz mit Flaschen übersät.
(Achtung, Rant-Character. Wer das nicht mag findet die Lösung in den letzten 3 Absätzen)
Heute also mal wieder Docker. Ein stetiger Quell an Problemen. Ursprünglich war meine Anforderung gar nicht so kompliziert: Per docker-compose soll eine Multi-Container-Applikation aus- und wieder eingeschaltet werden. Also: docker-compose down und warten. Leider scheiterte der Prozess bereits an dieser Stelle aufgrund eines Timeouts. Das Schreiben großer Caches beim Beenden benötigt eben seine Zeit. Sicher, es gäbe -t oder stop_grace_period, aber wie das oft so ist: Wer auch immer vorher damit gearbeitet hat, hat es natürlich nicht dokumentiert oder konfiguriert.
Nunja, der docker-daemon sollte die zugehörigen Container trotz des Timeouts im Frontend noch abarbeiten – entsprechend war nach kurzer Bedenkzeit in docker ps -a auch kein Container mehr zu sehen, der zur Applikation gehört.
Alles gut? Leider nein. Das folgende docker-compose up weigerte sich beharrlich die Container wieder zu starten. Es versuchte immer noch, die Überreste der alten Struktur, insbesondere die Netzwerke, zu löschen, und scheiterte:
ERROR: error while removing network: network application_network id XXX has active endpoints
Active? Interessant, denn in docker ps -a war ja definitiv nichts mehr aktiv. Auch ein manuelles docker network remove application_network behauptete weiterhin, dass es die ID noch gäbe.
Error response from daemon: error while removing network: network application_network id XXX has active endpoints.
Ein docker network inspect application_network verriet: Die nicht mehr gelisteten Container sind wohl doch noch da – zumindest so halb. Also gehen wir auf Zombie-Jagd.
Die Lösung: Erst trägt man mit docker network inspect application_network | grep Name die Namen der verbliebenen Containerreste zusammen. Im Anschluss kann man über docker network disconnect ein Entfernen erzwingen.
for i in application_db_1 application_es_1 application_redis_1 application_nginx_1 ;do docker network disconnect -f application_network $i ;done
Abschließend entfernt man mit docker network remove application_network das Netzwerk. Danach sollte einem erneuten Start nichts mehr im Wege stehen.
Touchpads sind an vielen Mobilgeräten verbreitet. Kompakter als eine Maus, genauer als ein Touchscreen. Wenn es darum geht, wie man diese Bedient, verfolgen verschiedene Hersteller jedoch unterschiedliche Konzepte. Meine bisherigen Laptops nutzten dabei folgende Methode: Zum (links)Klicken drückt man das Pad über den Druckpunkt, für einen Rechtsklick selbes spiel, während zwei Finger auf dem Touchpad sind. Ein neueres Modell mit ELAN-Touchpad fällt hier aus der Reihe: Der „normale“ Klick geht zwar auch über den Druckpunkt, für einen Rechtsklick muss man aber in der unteren, rechten Ecke mit einem Finger über den Druckpunkt kommen. Nervig, wenn man anderes gewohnt ist.
ELAN-Touchpad. Ein Drücken in der rot markierten Ecke löst einen Rechtsklick aus.
Glücklicherweise kann man unter xorg Abhilfe finden, wenn auch nicht sonderlich dokumentiert. Auf einer Textkonsole in der grafischen Oberfläche kann man mit xinput eine Liste der erkannten Geräte anzeigen lassen. Hier sucht man im Abschnitt Virtual core pointer den Eintrag, welcher das Touchpad sein könnte. Meist kommt dabei das Wort „Touchpad“ im Gerätenamen vor. In der zweiten Spalte findet man eine ID, diese merkt man sich für die nächsten Befehle.
Tipp: Alternativ zur ID kann man für die nächsten Befehle auch den vollen Gerätenamen nutzen. Mit Name ist die z.B. in Scripten weniger anfällig für spontane Neu-Nummerierungen, ist aber mehr Tipparbeit, daher hier mit IDs.
Nun lässt man sich mit xinput list-props 42 die möglichen Einstellungen ausgeben. 42 entspricht hierbei der zuvor ermittelten ID. Interessant sind hierbei unter anderem Folgende Punkte:
Tapping Enabled: Hiermit schaltet man das Tippverhalten um. Im Status 1 muss man zum Klicken das Touchpad nicht mehr über den Druckpunkt drücken, sondern nur den Finger anheben und das Touchpad kurz antippen. Mit zwei Fingern gibt es einen Rechtsklick, mit drei einen Mittelklick.
Tapping Button Mapping Enabled: Hier kann man wählen, ob man das „klassische“ Zwei Finger = Mittlere Maustaste und Drei Finger = Rechte Maustaste oder das heute eher übliche Zwei Finger = Rechte Maustaste und Drei Finger = Mittlere Maustaste nutzen möchte.
Scroll Method Enabled: Hier kann man den Scrollmodus ändern. Meist ist der erste Wert „twofinger“, also Scrollen durch hoch/runter wischen mit zwei Fingern, der Zweite „edge“, also Scrollen durch hoch/runterwischen am rechten Rand und der Dritte button, Also Scrollen durch Wischen bei gedrücktem (mittlerer?) Taste.
Disable While Typing Enabled: Selbsterklärend, oder? Schaltet das Touchpad aus, während man auf der Tastatur tippt.
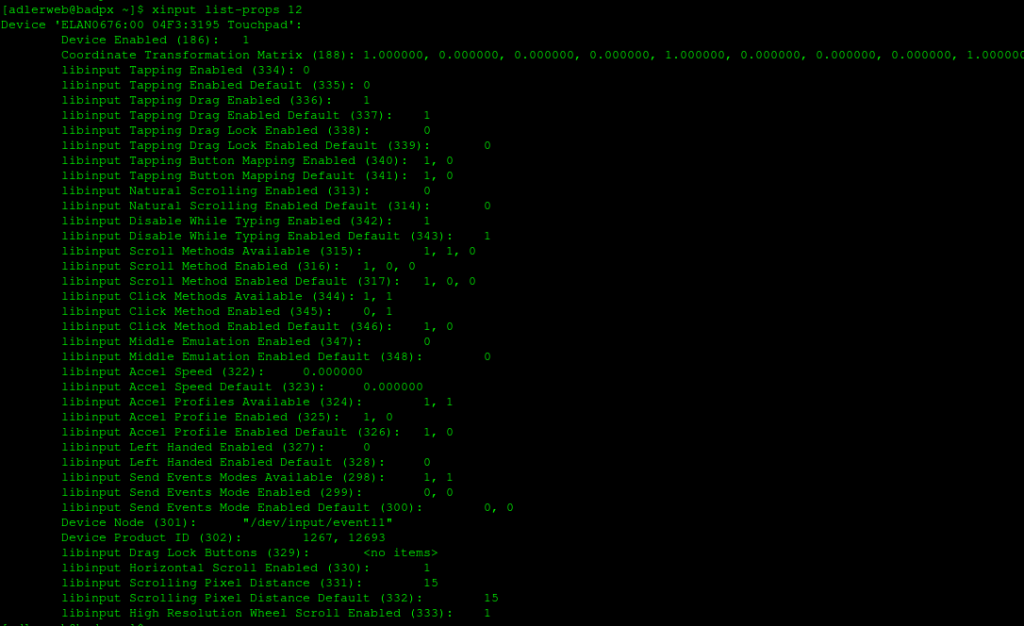
Click Method Enabled: Hier wird der Modus für das Klicken, also drücken über den Druckpunkt, bestimmt. Der erste Wert bedeutet „buttonareas“, also ein Rechtsklick durch einfaches drücken in der unteren, rechten Ecke. Der zweite Wert steht für „clickfinger“ und schaltet den Rechtsklick über zwei Finger ein.
Liste der Parameter eines ELAN-Touchpads
Um das von mir gewünschte Verhalten erbeizuführen muss also die Klick-Methode geändert werden. Hierbei kann nur eine der Optionen gewählt werden. Der Standard liegt bei „1, 0“, also buttonareas. Ein Ändern auf „0, 1“ bzw. clickfinger ist über folgenden Befehl möglich: xinput set-prop 42 245 0 1 – oder etwas lesbarer mit Geräte– und Optionsnamen xinput set-prop "ELAN0676:00 04F3:3195 Touchpad" 'libinput Click Method Enabled' 0 1.
Die Einstellung gilt dabei nur für die aktuelle X-Sitzung. Sollen diese Dauerhaft sein muss man die Einstellungen entweder über /etc/X11/xorg.conf.d/ vornehmen oder den obigen Befehl in den Autostart des Windowmanagers aufnehmen. Letzteres hat den Vorteil, dass die Einstellung nur für den aktuellen Nutzer gilt und man so unterschiedliche Vorlieben bedienen kann. Ich habe es entsprechend als exec in ~/.config/i3/config gepackt und kann jetzt wieder wie gewohnt rechtsklicken. Oder natürlich einfach ein paar cm weiter oben den roten Nippel nutzen und das Problem nicht haben.
In der Einfamilienhaussiedlung Bienenberg lässt der kleine Kevin drei Knallerbsen in der Einfahrt des Elternhauses zerplatzen. Neujahrsstimmung breitet sich aus. Die Freude ist groß.
Nebenhausen, 18:10
Beim Rauslassen der Katze beobachtet Nachbar Herbert B. die provokante Knalleroffensive im Nebenhaus. Umgehend begibt er sich zum Gertenschuppen, in dem Restbeständen des Jahrtausendwechsels noch in einer Schubkarre lagern.
Nebenhausen, 18:42
Herbert B. hat eine Tüte mit den Überresten unzähliger Mini-Böller Deutscher Herstellung entdeckt und ins Freie verfrachtet. Grimmig sortiert er zerbröselte Exemplare heraus und beginnt damit die Lunten der Reste anzuzünden.
Unter-Ober-Neustadt bei Nebenhausen, 18:51
In der Polizeidienststelle Unter-Ober-Neustadt gehen erste Besorgte Anrufe über unklare Explosionen ein. Der Diensthabende Wachtmeister Mayer wiegelt ab: Vorzeitige Detonationen seien normal, außerdem ist der einzige Kollege Schmidt grade Abendessen kaufen. Kann man nichts machen.
Nebenhausen, 19:04
Torben L. unterbricht das Abendessen um seinen Beitrag zum beginnenden Jahr zu leisten. Das Schmidt’sche Knallen wird alsbald durch extra aus dem Ausland bestellte Superböller ergänzt.
Nebenhausen, 19:11
Auch Timo N. bereitet sich auf seinen Einsatz vor. Ein Konstrukt aus Gewebeband, Polenböllern und diversen Chemikalien soll den Jahreswechsel unvergesslich machen und findet den Weg auf die Grundstücksmauer. Dummerweise ohne Feuerzeug, also nochmal suchen.
Nebenhausen, 19:16
Durch die ständigen Knallgeräusche fühlt sich Nadine Becker aus der Nachbarstraße beim Genuss des Senders RTL gestört. Aus der Handschuh-Schublade neben dem Hauseingang greift sie eine Leuchtpistole osteuropäischer Herstellung, welche Sie für Notfälle gekauft hat. Durch einen gezielten Schuss in dem Himmel verleit sie ihrem Unmut ausdruck.
Nebenhausen, 19:17
Das taghelle Flackern der offenbar etwas stärkeren Leuchtmunition erweckt das Interesse des kleinen Justin. Gemeinsam mit Freund Maurice schleichen sie sich über den Garten zum Haus von Timo N und entwenden dessen Eigenbausprengsatz.
Nebenhausen, 19:23
Torben und Maurice Zünden die Lunte, versenken das Konstrukt in einem zum Abwassersystem gehördenden Schacht und treten dir Flucht an. Den Deckel des Schachtes haben Betrunkene schon vor einigen Wochen abgehoben, durch die Weihnachtszeit konnte die Straßenmeisterei diesen noch nicht ersetzen. Kann man nix machen.
Nebenhausen, 19:24
Die Druckwelle der Detonation lößt einen Tsunami aus Kloschüssel, Waschbecken und Dusche des Alkoholikers Fritz aus, welcher seinen wohlverdienten Katerschlaf auf eben jenem Thron verbrachte. Ein kurzer Blick auf die drei Armbanduhren zeigt: Japp, ein Zeiger ist auf der Null. Vermutlich. Wankend begibt er sich zum Kleiderschrank mit Errungenschaften seiner Bundeswehrzeit um traditionsgemäß mit einer Übungshandgranate des Typs DM58 das neue Jahr zu begrüßen.
Nebenhausen, 19:59
Nachdem Fritz erfolgreich das Bier weggeworfen und einen guten Schluck aus der Handgranate genommen hat wird Nebenhausen von einer lauten Detonation erschüttert. Wachtmeister Mayer wirft einen kurzen Blick von seiner BILD-Zeitung – seltsame Uhrzeit, aber kann man nix machen.
Nebenhausen, 20:01
Beim Ausräumen der Spülmaschine durch den Knall erschreckt lässt Nachbarin Erna W. eine ihrer guten Meißen-Tassen fallen, welche einen teuren Scherbenhaufen auf dem Fußboden hinterlässt. Umgehend begibt sie sich ins Freie um nach dem Rechten zu sehen.
Nebenhausen, 20:05
Die Sirenen des Ortes treten in Aktion. Die Feuerwehr wird aufgefordert die Überreste des Akholikers Fritz im entstandenen Krater zusammenzusuchen. Der Rettungsdienst atmet nach der Funkdurchsage auf – doch kein zusätzliches Bett nötig.
Nebenhausen, 20:09
Der 85-jährige Kriegsveteran August R. interpretiert das Sirenensignal fälchlicherweise als anstehender Luftschlag. In einem verzweifelten Versuch die Region als bereits Zerstört darzustellen zündet er das Darstellungsmittel DM 25 elektrisch. Der 39kg schwere Prototyp erzeugt alsbald den Anschein einer Atombombenexplosion. Die 90m hohe und 45m breite Rauchwolke wäre sicher imposant, wenn man sie nach dem vorherigen Lichtblitz denn noch sehen könnte.
Nebenhausen, 21:50
In einer eilig einberufenen Pressekonferenz bedauern die Gesundheits-, Verkehrs- und Justizminister die massiven Zerstörungen in Nebenhausen sowie den angrenzenden Orten. Es handele sich um einen tragischen Unfall, welcher jedoch keine Auswirkungen auf die Verfügbarkeit von Böllern oder anderen Freiheiten der Bürger haben werde. Die angrenzende Autobahnbrücke werde in den nächsten Wochen durch ein Provisorium ersetzt. Die Bahnstrecke wird aus Kostengründen nicht wiederaufgebaut.






![[Testergebnisse]
1000BASE-T NO
100BASE-TX NO
10BASE-T YES
VoIP NO](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/sig02-1024x542.jpg)
![[1000BASE-T Ergebnisse]
SIGNAL LEISTUNG: FEHLER
Länge: 27.7m, OK
Wire-Map: 8+1 grade Striche, OK](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/sig01-1024x528.jpg)
![[1000BASE-T Ergebnisse]
X SIGNAL LEISTUNG
Paar: 36
Verteile Kabelfehler
Kabel prüfen](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/sig03-1024x546.jpg)
![[1000BASE-T Ergebnisse]
X SIGNAL LEISTUNG
Paar: 12
Verteilte Kabelfehler
Kabel prüfen](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/IMG_5458s-1024x524.jpg)


![[1000BASE-T Ergebnisse]
SIGNAL LEISTUNG: FEHLER
Länge: 13.4m, OK
Wiremap OK](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/IMG_5452s-1024x569.jpg)
![[1000BASE-T Ergebnisse]
SIGNAL LEISTUNG: FEHLER
Länge: 17.7m
Wiremap OK](https://www.adlerweb.info/blog/wp-content/uploads/2024/12/IMG_5455s-1024x535.jpg)